-

-
大数据培训:Kafka常见消息发送策略
Kafka作为实时数据流处理的分布式组件而言,性能是非常值得称赞的,从消息流的引入到传送,遵循相应的消息发送策略,来达到更高效地数据处理。今天的大数据培训分享,我们来具体...
查看详情 >>
-

-
大数据培训:MapReduce ReduceTask工作机制
MapReduce的分布式并行计算,分为Map和Reduce阶段,Map阶段的工作流程机制,前面已经为大家讲过了,今天我们接着来讲Reduce阶段。在Reduce阶段,Reduce Task的具体运行细节,需要大家去结合到...
查看详情 >>
-

-
大数据培训:MapReduce排序与合并机制
MapReduce作为Hadoop的核心计算引擎,算是学习当中必学的一个部分。虽然发展至今,MapReduce计算框架已经很少直接使用了,但是作为分布式并行计算的代表,还是值得学习。今天的大数据...
查看详情 >>
-

-
大数据培训:ZooKeeper的高可用和CPA理论
Zookeeper作为分布式服务实现的重要支持组件之一,在分布式集群环境下,要保证其高可用性,这就涉及到很注明的CPA理论。今天的大数据培训学习分享,我们就主要来讲讲ZooKeeper的高可...
查看详情 >>
-

-
大数据培训:MongoDB哈希分片讲解
MongoDB作为分布式集群环境下常用的数据库之一,在完成相应的存储任务时,往往涉及到数据分片的问题。今天的大数据培训分享,我们就主要来讲讲MongoDB的哈希分片。 哈希分片使用哈...
查看详情 >>
-
-
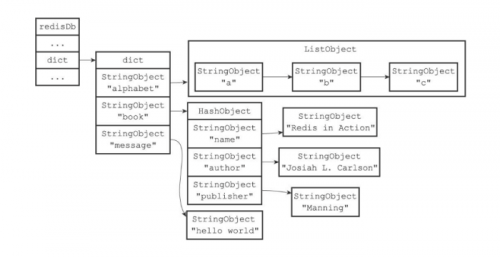
大数据培训:Redis数据库与TTL过期处理
作为大数据生态下备受关注的NOSQL数据库之一,Redis的重要性相信不必特意强调。Redis的存储模式,是键值对存储,包含多种数据结构、支持网络、基于内存、可选持久性。今天的大数据...
查看详情 >>
-
-
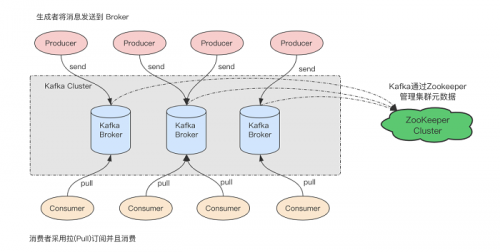
大数据培训:Kafka主题与分区概念详解
Kafka作为大数据生态的重要组件,尤其在实时消息流处理上,有明显的优势,而Kafka的性能优势,与Kafka的架构有关。今天的大数据培训分享,我们就主要来讲讲Kafka当中的两个重要概念,...
查看详情 >>
-

-
大数据培训:Flink状态类型讲解
Flink作为流计算代表性的框架,这几年在国内的热度上升很快,国内互联网大厂都在逐步引入Flink。Flink的定义当中,有一条是进行有状态的流计算,这就涉及到状态这个概念。今天的大...
查看详情 >>






