大数据培训:Kafka主题与分区概念详解
作者:张老师 浏览次数: 2021-06-04 17:01
Kafka作为大数据生态的重要组件,尤其在实时消息流处理上,有明显的优势,而Kafka的性能优势,与Kafka的架构有关。今天的大数据培训分享,我们就主要来讲讲Kafka当中的两个重要概念,主题与分区。
主题(Topic)与分区(Partition)
Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到Kafka集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。
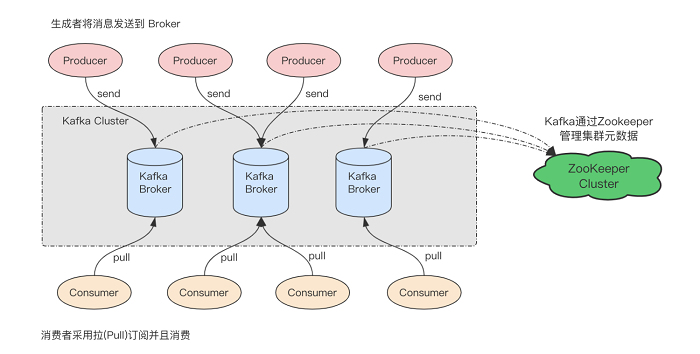
主题是一个逻辑上的概念,它还可以细分为多个分区,一个分区只属于单个主题,很多时候也会把分区称为主题分区(Topic-Partition)。同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序。
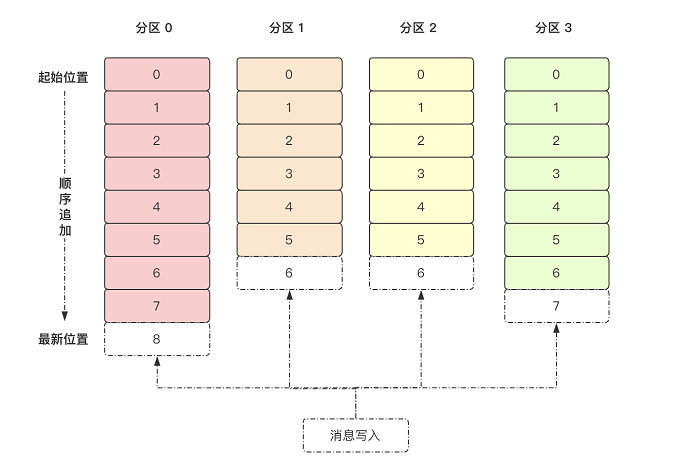
如上图所示,主题中有4个分区,消息被顺序追加到每个分区日志文件的尾部。Kafka中的分区可以分布在不同的服务器(broker)上,也就是说,一个主题可以横跨多个broker,以此来提供比单个broker更强大的性能。
每一条消息被发送到broker之前,会根据分区规则选择存储到哪个具体的分区。如果分区规则设定得合理,所有的消息都可以均匀地分配到不同的分区中。如果一个主题只对应一个文件,那么这个文件所在的机器I/O将会成为这个主题的性能瓶颈,而分区解决了这个问题。在创建主题的时候可以通过指定的参数来设置分区的个数,当然也可以在主题创建完成之后去修改分区的数量,通过增加分区的数量可以实现水平扩展。
Kafka为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。
同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个broker失效时仍然能保证服务可用。

如上图所示,Kafka集群中有4个broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个leader副本和2个follower副本。生产者和消费者只与leader副本进行交互,而follower副本只负责消息的同步,很多时候follower副本中的消息相对leader副本而言会有一定的滞后。
Kafka消费端也具备一定的容灾能力。Consumer使用拉(Pull)模式从服务端拉取消息,并且保存消费的具体位置,当消费者宕机后恢复上线时可以根据之前保存的消费位置重新拉取需要的消息进行消费,这样就不会造成消息丢失。
关于大数据培训,Kafka主题与分区概念,以上就为大家做了基本的介绍了。学习Kafka,对于内部的很多概念,是需要自己去理清楚的,并且还要结合到实际运行机制去理解,才能更加透彻。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服获取!
主题(Topic)与分区(Partition)
Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到Kafka集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。
主题是一个逻辑上的概念,它还可以细分为多个分区,一个分区只属于单个主题,很多时候也会把分区称为主题分区(Topic-Partition)。同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序。
如上图所示,主题中有4个分区,消息被顺序追加到每个分区日志文件的尾部。Kafka中的分区可以分布在不同的服务器(broker)上,也就是说,一个主题可以横跨多个broker,以此来提供比单个broker更强大的性能。
每一条消息被发送到broker之前,会根据分区规则选择存储到哪个具体的分区。如果分区规则设定得合理,所有的消息都可以均匀地分配到不同的分区中。如果一个主题只对应一个文件,那么这个文件所在的机器I/O将会成为这个主题的性能瓶颈,而分区解决了这个问题。在创建主题的时候可以通过指定的参数来设置分区的个数,当然也可以在主题创建完成之后去修改分区的数量,通过增加分区的数量可以实现水平扩展。
Kafka为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。
同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个broker失效时仍然能保证服务可用。
如上图所示,Kafka集群中有4个broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个leader副本和2个follower副本。生产者和消费者只与leader副本进行交互,而follower副本只负责消息的同步,很多时候follower副本中的消息相对leader副本而言会有一定的滞后。
Kafka消费端也具备一定的容灾能力。Consumer使用拉(Pull)模式从服务端拉取消息,并且保存消费的具体位置,当消费者宕机后恢复上线时可以根据之前保存的消费位置重新拉取需要的消息进行消费,这样就不会造成消息丢失。
关于大数据培训,Kafka主题与分区概念,以上就为大家做了基本的介绍了。学习Kafka,对于内部的很多概念,是需要自己去理清楚的,并且还要结合到实际运行机制去理解,才能更加透彻。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服获取!
- 上一篇:HTML中的内联框架及进阶设计
- 下一篇:大数据学习:Spark资源参数调优建议




