-
-
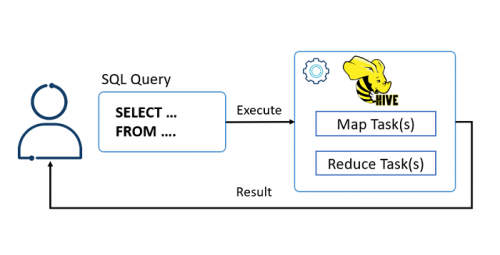
大数据培训:Hive DML操作入门
前面讲了Hive DDL操作,基本上与SQL的基本操作类似,有相关的基础的话,理解掌握起来是非常快的。而DML部分,主要是涉及到增删改,也可以对比着来理解掌握。今天的大数据培训分享,...
查看详情 >>
-
-
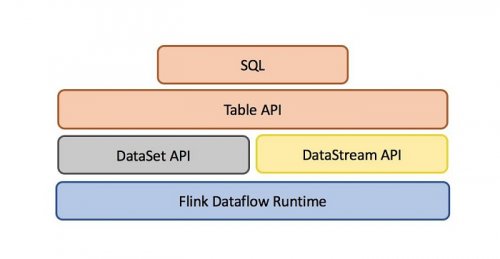
大数据培训:Flink关系型API是什么
在Flink编程当中,很重要的一个概念是API编程,Flink提供多种类型的API,去完成相应的编程任务。今天的大数据培训分享,我们来做个初步的入门,Flink关系型API是什么? 在接触关系型...
查看详情 >>
-
-
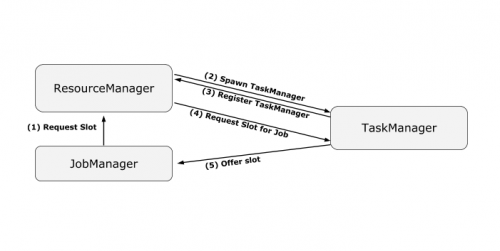
大数据培训:Flink守护进程容错
之前我们已经讲了Flink的作业执行容错机制,这是Flink容错机制的重要一环,而在作业执行层面的容错之外,守护进程容错也是一个重要的容错方案。今天的大数据培训分享,我们就来讲...
查看详情 >>
-
-
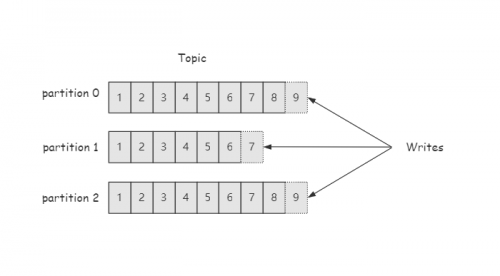
大数据培训:Kafka文件存储和分区机制
Kafka在实时消息流的处理上,为确保消息数据的稳定和可靠性,在存储上引入了相应的手段,比如说分区。今天的大数据培训分享,我们就具体来讲讲Kafka文件存储和分区机制。 kafka文件...
查看详情 >>
-

-
大数据培训:Spark和Spark Streaming的区别
作为业界主流的开源大数据处理框架之一,Spark的地位还是值得肯定的。在面对大规模的离线批处理任务上,Spark性能优异,同时又有Spark Streaming来负责流计算处理。今天的大数据培训分...
查看详情 >>
-

-
大数据培训:Hive表的基本操作
针对于Hive表的操作,是Hive当中需要大家付出足够的精力去学习和掌握的。Hive所支持的类SQL语言HQL,如果自身有比较好的SQL基础的话,其实很多东西也是能够快速融会贯通的。今天的大...
查看详情 >>
-

-
大数据培训:详解Kafka控制器初始化
Kafka作为分布式消息队列而言,确实为海量的实时消息流处理提供了可靠的解决方案,其生产者、消费者的模式,确保了消息流处理的效率。今天的大数据培训分享,我们主要来讲讲,...
查看详情 >>
-

-
大数据培训:Redis如何选择RDB和AOF
Redis作为内存数据库,优势是数据读写性能非常的赞,因为数据被存储在内存当中,但是同时也面临着各种意外状况可能造成的数据丢失,这就需要持久化来进行备份与恢复。Redis有RDB和...
查看详情 >>






