大数据培训:Kafka文件存储和分区机制
作者:张老师 浏览次数: 2021-03-18 17:45
Kafka在实时消息流的处理上,为确保消息数据的稳定和可靠性,在存储上引入了相应的手段,比如说分区。今天的大数据培训分享,我们就具体来讲讲Kafka文件存储和分区机制。
kafka文件存储机制
在kafka中生产者(producer)是面向主题(topic)生产数据,但是topic只是逻辑上的概念,在实际的文件存储中,生产者生产的数据是以每个topic中分区来形成的存储文件。
例如:某个topic有三个分区,会在实际的物理存储中形成三个文件,文件命名的格式为:topic名称+分区序号。topic名称是first,则三个文件名字是:first-0,first-1,first-2。
同时因为断的生产数据,为了防止文件过大,导致消费者消费数据,找寻读取数据的速度变慢,kafka设计了分片和索引机制,将每个分区会形成多个segment。每个segment又对应两个文件——“.index”文件和“.log”文件。
当写入数据当一定阶段,会自动生成下一个segment,从segment0到segment1,每个segment中index和log文件以当前segment的第一条消息的offset命名。“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
Kafka消息分区机制
①Topic分区
首先简单说一下分区的概念,可以用下图表示:
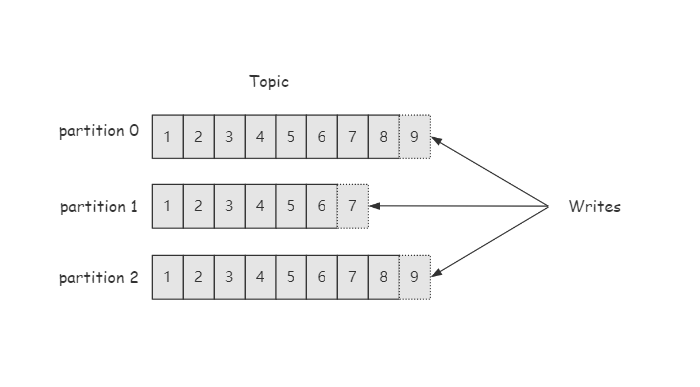
分区即partition是Kafka中非常重要的概念,分区的作用主要是为Kafka提供负载均衡的能力,同时也是Kafka高吞吐量的保证。生产端要将数据发送到具体topic的某一个分区中,并且消息只在分区内有序。
②分区器
消息通过send方法发送过程中,可能会经过分区器(Partitioner)的作用才能发往broker端。如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。
Kafka提供了默认分区器o.a.k.clients.producer.internals.DefaultPartitioner,并通过其partition()定义主要的分区分配逻辑。接下来我们看一下Kafka相关的分区策略。
③分区策略
所谓分区策略就是决定消息发往具体分区所采用的算法或逻辑。目前Kafka主要提供两种分区策略:哈希策略与轮询策略。
当没有为消息指定key即key为null时,消息会以轮询的方式发送到各个分区(各个版本实现可能不一样,还有一种随机策略,有待考证);当key不为null时,默认分区器会使用key的哈希值(采用Murmur2Hash算法)对partition数量取模,决定要把消息发送到哪个partition上。
关于大数据培训,Kafka文件存储和分区机制,以上就为大家做了大致的介绍了。理解和掌握Kafka的文件存储和分区机制,对于Kafka组件而言,是非常重要的一部分,建议大家一定要深入搞懂。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础就业班本月正在招生中,课程大纲及课程视频可联系客服获取!
kafka文件存储机制
在kafka中生产者(producer)是面向主题(topic)生产数据,但是topic只是逻辑上的概念,在实际的文件存储中,生产者生产的数据是以每个topic中分区来形成的存储文件。
例如:某个topic有三个分区,会在实际的物理存储中形成三个文件,文件命名的格式为:topic名称+分区序号。topic名称是first,则三个文件名字是:first-0,first-1,first-2。
同时因为断的生产数据,为了防止文件过大,导致消费者消费数据,找寻读取数据的速度变慢,kafka设计了分片和索引机制,将每个分区会形成多个segment。每个segment又对应两个文件——“.index”文件和“.log”文件。
当写入数据当一定阶段,会自动生成下一个segment,从segment0到segment1,每个segment中index和log文件以当前segment的第一条消息的offset命名。“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
Kafka消息分区机制
①Topic分区
首先简单说一下分区的概念,可以用下图表示:
分区即partition是Kafka中非常重要的概念,分区的作用主要是为Kafka提供负载均衡的能力,同时也是Kafka高吞吐量的保证。生产端要将数据发送到具体topic的某一个分区中,并且消息只在分区内有序。
②分区器
消息通过send方法发送过程中,可能会经过分区器(Partitioner)的作用才能发往broker端。如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。
Kafka提供了默认分区器o.a.k.clients.producer.internals.DefaultPartitioner,并通过其partition()定义主要的分区分配逻辑。接下来我们看一下Kafka相关的分区策略。
③分区策略
所谓分区策略就是决定消息发往具体分区所采用的算法或逻辑。目前Kafka主要提供两种分区策略:哈希策略与轮询策略。
当没有为消息指定key即key为null时,消息会以轮询的方式发送到各个分区(各个版本实现可能不一样,还有一种随机策略,有待考证);当key不为null时,默认分区器会使用key的哈希值(采用Murmur2Hash算法)对partition数量取模,决定要把消息发送到哪个partition上。
关于大数据培训,Kafka文件存储和分区机制,以上就为大家做了大致的介绍了。理解和掌握Kafka的文件存储和分区机制,对于Kafka组件而言,是非常重要的一部分,建议大家一定要深入搞懂。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础就业班本月正在招生中,课程大纲及课程视频可联系客服获取!
- 上一篇:数据分析岗位必须要学习各项编程语言吗?
- 下一篇:大数据学习:Kafka副本机制详解




