大数据培训:Spark动态内存管理模式
作者:张老师 浏览次数: 2021-02-03 17:41
Spark的运行机制当中,内存管理和应用是非常关键的一个环节,而在Spark 1.6之后的版本当中,动态内存管理模式上线,对于内存管理这个模块来说,也有了新变化。今天的大数据培训分享,我们就主要来讲讲,Spark动态内存管理模式。

spark从1.6版本以后,默认的内存管理方式就调整为统一内存管理模式,由UnifiedMemoryManager实现。
Spark内存组成部分
Unified MemoryManagement模型,重点是打破运行内存和存储内存之间的界限,使spark在运行时,不同用途的内存之间可以实现互相的拆借。Spark每个executor(JVM)内存由一下几个部分组成:
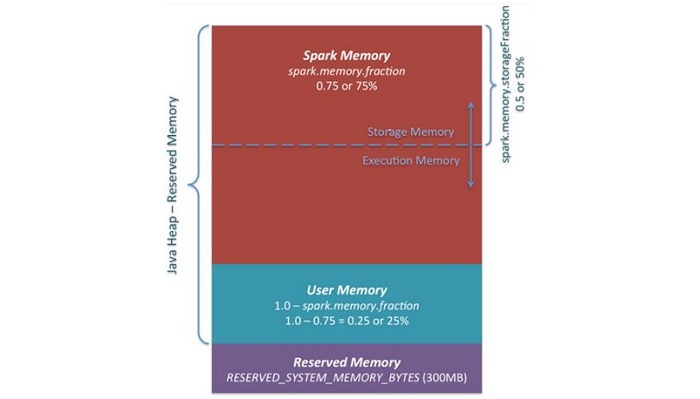
①Reserved Memory:这部分内存是预留给系统使用,在1.6.0默认为300MB,这一部分内存不计算在spark execution和storage中。可通过spark.testing.reservedMemory进行设置。然后把实际可用内存减去这个reservedMemory得到usableMemory。ExecutionMemory和StorageMemory会共享usableMemory*spark.memory.fraction(默认0.75)。
②User Memory:分配Spark Memory剩余的内存,用户可以根据需要使用。默认占(Java Heap-Reserved Memory)*0.25。
③Spark Memory:计算方式为(Java Heap–ReservedMemory)*spark.memory.fraction,在1.6.0中,默认为(Java Heap-300M)*0.75。Spark Memory又分为Storage Memory和Execution Memory两部分。两个边界由spark.memory.storageFraction设定,默认为0.5。
Spark动态内存管理设计理念
相对于静态内存模型(即存储和运行内存相互隔离、彼此不可拆借),动态内存实现了存储和计算内存的动态拆借。也就是说,当计算内存超了,它会从空闲的存储内存中借一部分内存使用,存储内存不够用的时候,也会向空闲的计算内存中拆借。值
得注意的地方是,被借走用来执行运算的内存,在执行完任务之前是不会释放内存的。通俗的讲,运行任务会借存储的内存,但是它直到执行完以后才能归还内存。
和动态内存相关的参数如下:
spark.memory.fraction(默认0.75):这个参数用来配置存储和计算内存占整个jvm的比例。这个参数设置的越低,也就是存储和计算内存占jvm的比例越低,就越可能频繁的发生内存的释放(将内存中的数据写磁盘或者直接丢弃掉)。
反之,如果这个参数越高,发生释放内存的可能性就越小。这个参数的目的是在jvm中留下一部分空间用来保存spark内部数据,用户数据结构,并且防止对数据的错误预估可能造成OOM的风险。
spark.memory.storageFraction(默认0.5):在spark.memory.fraction中存储内存所占的比例,默认是0.5,如果使用的存储内存超过了这个范围,缓存的数据会被驱赶。
spark.memory.useLegacyMode(default false):设置是否使用saprk1.5及以前遗留的内存管理模型,即静态内存模型,上一篇文章我们介绍过这个,主要是设置以下几个参数:
spark.storage.memoryFraction
spark.storage.safetyFraction
spark.storage.unrollFraction
spark.shuffle.memoryFraction
spark.shuffle.safetyFraction
关于大数据培训,Spark动态内存管理模式,以上就为大家做了简单的介绍了。在大数据生态圈,Spark的地位不容置疑,而Spark的内存管理部分,对于后续的优化也是紧密关联的。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及学习视频可联系客服获取!
spark从1.6版本以后,默认的内存管理方式就调整为统一内存管理模式,由UnifiedMemoryManager实现。
Spark内存组成部分
Unified MemoryManagement模型,重点是打破运行内存和存储内存之间的界限,使spark在运行时,不同用途的内存之间可以实现互相的拆借。Spark每个executor(JVM)内存由一下几个部分组成:
①Reserved Memory:这部分内存是预留给系统使用,在1.6.0默认为300MB,这一部分内存不计算在spark execution和storage中。可通过spark.testing.reservedMemory进行设置。然后把实际可用内存减去这个reservedMemory得到usableMemory。ExecutionMemory和StorageMemory会共享usableMemory*spark.memory.fraction(默认0.75)。
②User Memory:分配Spark Memory剩余的内存,用户可以根据需要使用。默认占(Java Heap-Reserved Memory)*0.25。
③Spark Memory:计算方式为(Java Heap–ReservedMemory)*spark.memory.fraction,在1.6.0中,默认为(Java Heap-300M)*0.75。Spark Memory又分为Storage Memory和Execution Memory两部分。两个边界由spark.memory.storageFraction设定,默认为0.5。
Spark动态内存管理设计理念
相对于静态内存模型(即存储和运行内存相互隔离、彼此不可拆借),动态内存实现了存储和计算内存的动态拆借。也就是说,当计算内存超了,它会从空闲的存储内存中借一部分内存使用,存储内存不够用的时候,也会向空闲的计算内存中拆借。值
得注意的地方是,被借走用来执行运算的内存,在执行完任务之前是不会释放内存的。通俗的讲,运行任务会借存储的内存,但是它直到执行完以后才能归还内存。
和动态内存相关的参数如下:
spark.memory.fraction(默认0.75):这个参数用来配置存储和计算内存占整个jvm的比例。这个参数设置的越低,也就是存储和计算内存占jvm的比例越低,就越可能频繁的发生内存的释放(将内存中的数据写磁盘或者直接丢弃掉)。
反之,如果这个参数越高,发生释放内存的可能性就越小。这个参数的目的是在jvm中留下一部分空间用来保存spark内部数据,用户数据结构,并且防止对数据的错误预估可能造成OOM的风险。
spark.memory.storageFraction(默认0.5):在spark.memory.fraction中存储内存所占的比例,默认是0.5,如果使用的存储内存超过了这个范围,缓存的数据会被驱赶。
spark.memory.useLegacyMode(default false):设置是否使用saprk1.5及以前遗留的内存管理模型,即静态内存模型,上一篇文章我们介绍过这个,主要是设置以下几个参数:
spark.storage.memoryFraction
spark.storage.safetyFraction
spark.storage.unrollFraction
spark.shuffle.memoryFraction
spark.shuffle.safetyFraction
关于大数据培训,Spark动态内存管理模式,以上就为大家做了简单的介绍了。在大数据生态圈,Spark的地位不容置疑,而Spark的内存管理部分,对于后续的优化也是紧密关联的。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及学习视频可联系客服获取!




