-

-
大数据学习:从Spark到Spark Streaming
Apache Spark作为大数据技术领域的第二代代表性框架,其江湖地位是得到肯定的。第一代的Hadoop框架,为大数据基础架构打下坚实的基础,而Spark为更高性能的数据计算提供了新的解决方案...
查看详情 >>
-

-
大数据学习:Spark Streaming vs Structured Streaming
在Spark框架当中,其负责流计算任务的组件,主要是Spark Streaming,但是随着大数据继续发展,Spark Streaming也开始有了各种场景下的局限,于是又推出了Structured Streaming。今天的大数据学习...
查看详情 >>
-

-
大数据学习:Spark Structured Streaming特性
在Spark框架当中,早期的设计由Spark Streaming来负责实现流计算,但是随着现实需求的发展变化,Spark streaming的局限也显露了出来,于是Spark团队又设计了Spark Structured Streaming。今天的大数...
查看详情 >>
-
-
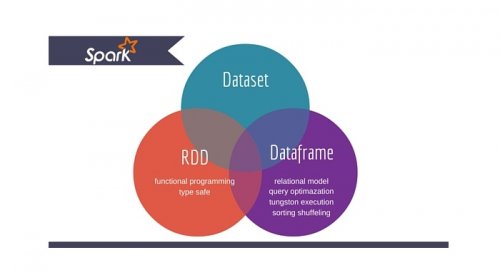
大数据培训:Spark RDD、DataFrame、DataSet
在Spark的学习当中,RDD、DataFrame、DataSet可以说都是需要着重理解的专业名词概念。尤其是在涉及到数据结构的部分,理解清楚这三者的共性与区别,非常有必要。今天的大数据培训分享...
查看详情 >>
-

-
大数据培训:流处理框架Spark Streaming与Storm
众所周知,大数据计算的第一代框架Hadoop,是致力于解决离线计算的问题而产生的,在离线批处理上性能优异,但是在实时流处理上,一直被诟病。Hadoop之后,Spark和Storm在流处理上成为...
查看详情 >>
-

-
大数据学习:如何创建Spark RDD
对Spark稍有了解的人都知道,Spark核心的数据结构,是弹性分布式数据集RDD,RDD作为Spark对数据的核心抽象,在编程任务当中,往往需要用到。今天的大数据学习分享,我们就主要来讲讲...
查看详情 >>
-
-
大数据学习:Kafka控制器解析
深入到Kafka内部,涉及到的诸多名词和概念,都需要去深入地学习掌握。以kafka控制器来说,这是Kafka的核心内部组件,对于kafka集群的管理和协调有重要作用。今天的大数据学习分享,我...
查看详情 >>
-

-
大数据学习:Kafka producer设计原理
关于Kafka这个组件,作为大数据技术生态当中流行的消息组件,得到越来越多的市场认可,kafka与大数据技术生态的诸多组件,也能实现很好地集成,地位也越来越稳固。今天的大数据学...
查看详情 >>
-

-
大数据培训:Spark持久化存储策略
持久化存储是Spark非常重要的一个特性,通过持久化存储,提升Spark应用性能,以更好地满足实际需求。而Spark的持久化存储,根据不同的需求现状,可以选择不同的策略方案。今天的大...
查看详情 >>






