-

-
大数据培训:Flink on Yarn原理
在流计算越来越受到重视的大趋势下,Flink框架受到的关注和重视,可以说是与日俱增,在大数据的学习当中,Flink也成为重要的一块。今天的大数据培训分享,我们主要来讲讲,Flink...
查看详情 >>
-
-
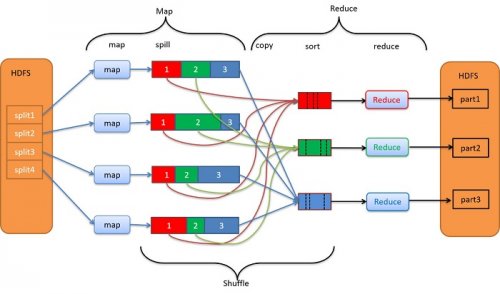
大数据学习: MapReduce Shuffle过程
在大数据计算框架当中,MapReduce无疑是典型的代表,作为Hadoop原生的计算引擎,在批处理上尤其具备优势,而后来为我们所熟知的Spark框架,也是继承了MapReduce的核心思想。今天的大数据...
查看详情 >>
-
-
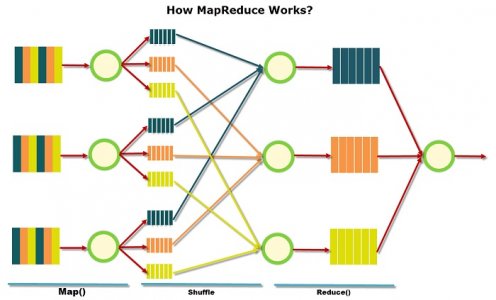
大数据学习:MapReduce编程模型
Hadoop当中的MapReduce,作为核心计算引擎,主要负责大规模离线数据的处理,至今仍然是非常经典的一代框架。对于MapReduce的学习,我们重点要掌握其编程模型。今天的大数据学习分享,...
查看详情 >>
-

-
大数据培训:MapReduce任务流程
作为Hadoop生态核心组件的MapReduce,是实现大数据计算处理的主要引擎,其核心思想是分而治之,简单来说就是分为Map和Reduce两个阶段。今天的大数据培训分享,我们主要来讲讲MapReduce具...
查看详情 >>
-

-
大数据学习:Hive调优的几种思路
在大数据技术生态当中,Hive调优是实际运行当中常常面临的问题,企业级的数据平台,随着数据规模的不断增长,要想更高效率地运行下去,就需要根据实际情况来进行优化。今天的大...
查看详情 >>
-
-
大数据学习:HDFS Federation(联邦)讲解
时至今日,大数据技术生态当中,Hadoop依然占据重要的位置,从1.X到2.X,Hadoop也在不断更新迭代,以解决实际应用场景当中遇到的新问题。在Hadoop 2.X的版本当中,引入了Federation(联邦机...
查看详情 >>
-

-
大数据培训:HDFS的故障恢复和高可用
作为分布式文件系统的HDFS,在Hadoop技术生态当中,始终是不容忽视的。HDFS的稳定性和可靠性,对于后续的数据处理环节,提供底层支持,起着至关重要的作用。今天的大数据培训分享,...
查看详情 >>
-
-
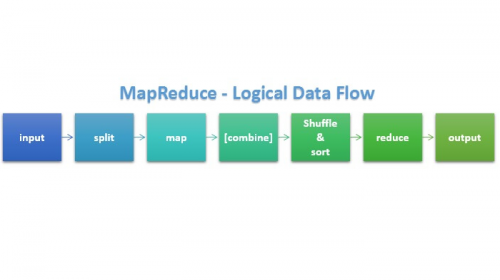
大数据学习:MapReduce分片阶段详解
MapReduce作为第一代的大数据计算引擎,其经典地位至今仍然得到认可,MapReduce之后的Spark计算引擎,本质上来说,依然是借用了MapReduce的核心思想。今天的大数据学习分享,我们就主要来...
查看详情 >>
-

-
大数据学习:分布式文件系统存储持久化策略
在大数据基础架构当中,分布式文件系统的存在,提供了一个低成本的大规模数据存储解决方案,而处于多数据安全和可用性的考虑,分布式文件系统的一个重要举措就是持久化。今天...
查看详情 >>






