大数据学习:分布式文件系统的伸缩性设计
作者:张老师 浏览次数: 2020-12-30 17:15
Hadoop当中负责分布式存储的HDFS,被定义为分布式文件系统,对于进入到平台当中的数据,提供高效的、可容错、可扩展的数据存储,这得益于分布式文件系统的一个重要特性——伸缩性。今天的大数据学习分享,我们就来讲讲分布式文件系统的伸缩性设计。
分布式文件系统当中,主从式的架构设计,使得伸缩性也基于存储节点和中心节点两个层面去实现。
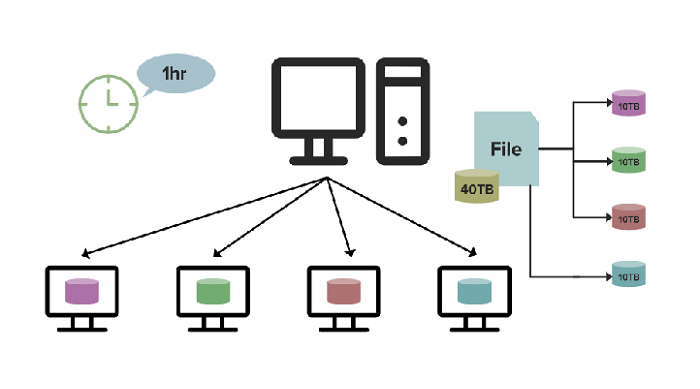
1、存储节点的伸缩
当在集群中加入一台新的存储节点,则它主动向中心节点注册,提供自己的信息,当后续有创建文件或者给已有文件增加数据块的时候,中心节点就可以分配到这台新节点了,比较简单。但同时也需要解决一些相应产生的问题——
1)如何尽量使各存储节点的负载相对均衡?
首先要有评价存储节点负载的指标。可以从磁盘空间使用率考虑,也可以从磁盘使用率+CPU使用情况+网络流量情况等做综合判断。一般来说,磁盘使用率是核心指标。
其次在分配新空间的时候,优先选择资源使用率小的存储节点;而对已存在的存储节点,如果负载已经过载、或者资源使用情况不均衡,则需要做数据迁移。
2)怎样保证新加入的节点,不会因短期负载压力过大而崩塌?
当系统发现当前新加入了一台存储节点,显然它的资源使用率是最低的,那么所有的写流量都路由到这台存储节点来,那就可能造成这台新节点短期负载过大。因此,在资源分配的时候,需要有预热时间,在一个时间段内,缓慢地将写压力路由过来,直到达成新的均衡。
3)如果需要数据迁移,那如何使其对业务层透明?
在有中心节点的情况下,这个工作比较好做,中心节点就包办了——判断哪台存储节点压力较大,判断把哪些文件迁移到何处,更新自己的meta信息,迁移过程中的写入怎么办,发生重命名怎么办,无需上层应用来处理。
如果没有中心节点,那代价比较大,在系统的整体设计上,也是要考虑到这种情况,比如ceph,它要采取逻辑位置和物理位置两层结构,对Client暴露的是逻辑层(pool和place group),这个在迁移过程中是不变的,而下层物理层数据块的移动,只是逻辑层所引用的物理块的地址发生了变化,在Client看来,逻辑块的位置并不会发生改变。
2、中心节点的伸缩
如果有中心节点,还要考虑它的伸缩性。由于中心节点作为控制中心,是主从模式,那么在伸缩性上就受到比较大的限制,是有上限的,不能超过单台物理机的规模。我们可以考虑各种手段,尽量地抬高这个上限。有几种方式可以考虑:
以大数据块的形式来存储文件——比如HDFS的数据块的大小是64M,ceph的的数据块的大小是4M,都远远超过单机文件系统的4k。它的意义在于大幅减少meta data的数量,使中心节点的单机内存就能够支持足够多的磁盘空间meta信息。
中心节点采取多级的方式——顶级中心节点只存储目录的meta data,其指定某目录的文件去哪台次级总控节点去找,然后再通过该次级总控节点找到文件真正的存储节点;
中心节点共享存储设备——部署多台中心节点,但它们共享同一个存储外设/数据库,meta信息都放在这里,中心节点自身是无状态的。这种模式下,中心节点的请求处理能力大为增强,但性能会受一定影响。
关于大数据学习,分布式文件系统的伸缩性设计,以上就为大家做了简单的介绍了。关于伸缩性,这是影响分布式文件系统性能的重要指标之一,在架构层面就需要先做好构想。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试听课程可联系客服获取!
分布式文件系统当中,主从式的架构设计,使得伸缩性也基于存储节点和中心节点两个层面去实现。
1、存储节点的伸缩
当在集群中加入一台新的存储节点,则它主动向中心节点注册,提供自己的信息,当后续有创建文件或者给已有文件增加数据块的时候,中心节点就可以分配到这台新节点了,比较简单。但同时也需要解决一些相应产生的问题——
1)如何尽量使各存储节点的负载相对均衡?
首先要有评价存储节点负载的指标。可以从磁盘空间使用率考虑,也可以从磁盘使用率+CPU使用情况+网络流量情况等做综合判断。一般来说,磁盘使用率是核心指标。
其次在分配新空间的时候,优先选择资源使用率小的存储节点;而对已存在的存储节点,如果负载已经过载、或者资源使用情况不均衡,则需要做数据迁移。
2)怎样保证新加入的节点,不会因短期负载压力过大而崩塌?
当系统发现当前新加入了一台存储节点,显然它的资源使用率是最低的,那么所有的写流量都路由到这台存储节点来,那就可能造成这台新节点短期负载过大。因此,在资源分配的时候,需要有预热时间,在一个时间段内,缓慢地将写压力路由过来,直到达成新的均衡。
3)如果需要数据迁移,那如何使其对业务层透明?
在有中心节点的情况下,这个工作比较好做,中心节点就包办了——判断哪台存储节点压力较大,判断把哪些文件迁移到何处,更新自己的meta信息,迁移过程中的写入怎么办,发生重命名怎么办,无需上层应用来处理。
如果没有中心节点,那代价比较大,在系统的整体设计上,也是要考虑到这种情况,比如ceph,它要采取逻辑位置和物理位置两层结构,对Client暴露的是逻辑层(pool和place group),这个在迁移过程中是不变的,而下层物理层数据块的移动,只是逻辑层所引用的物理块的地址发生了变化,在Client看来,逻辑块的位置并不会发生改变。
2、中心节点的伸缩
如果有中心节点,还要考虑它的伸缩性。由于中心节点作为控制中心,是主从模式,那么在伸缩性上就受到比较大的限制,是有上限的,不能超过单台物理机的规模。我们可以考虑各种手段,尽量地抬高这个上限。有几种方式可以考虑:
以大数据块的形式来存储文件——比如HDFS的数据块的大小是64M,ceph的的数据块的大小是4M,都远远超过单机文件系统的4k。它的意义在于大幅减少meta data的数量,使中心节点的单机内存就能够支持足够多的磁盘空间meta信息。
中心节点采取多级的方式——顶级中心节点只存储目录的meta data,其指定某目录的文件去哪台次级总控节点去找,然后再通过该次级总控节点找到文件真正的存储节点;
中心节点共享存储设备——部署多台中心节点,但它们共享同一个存储外设/数据库,meta信息都放在这里,中心节点自身是无状态的。这种模式下,中心节点的请求处理能力大为增强,但性能会受一定影响。
关于大数据学习,分布式文件系统的伸缩性设计,以上就为大家做了简单的介绍了。关于伸缩性,这是影响分布式文件系统性能的重要指标之一,在架构层面就需要先做好构想。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试听课程可联系客服获取!
- 上一篇:大数据学习:Hbase数据结构与算法
- 下一篇:大数据培训:Hive小文件合并




