-

-
大数据学习:Apache Flink如何管理内存
Apache Flink的流计算,在实际的运行过程当中,对于内存的管理和调优,是非常关键的一环。今天的大数据学习分享,我们来讲讲,Apache Flink如何管理内存? Apache Flink内存管理,涉及到自...
查看详情 >>
-

-
大数据学习:Flink内存模型简介
作为新一代备受关注的流计算框架,Flink受到的关注越来越多,而Flink的学习,也成为大数据框架学习的一个重要部分。今天的大数据学习分享,我们就主要来讲讲Flink内存模型的部分。...
查看详情 >>
-
-
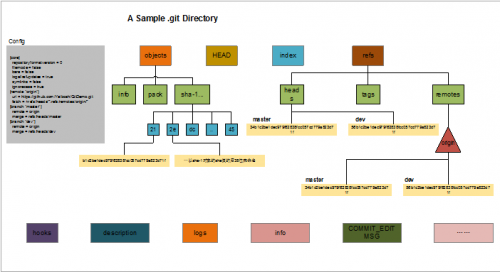
大数据开发:Git工作原理解析
一. Git的基本原理 本质上,Git是一套内容寻址(content-addressable)文件系统,而和我们直接接触的Git界面,只不过是封装在其之上的一个应用层。这个关系颇有点类似于计算机网络中应...
查看详情 >>
-
-
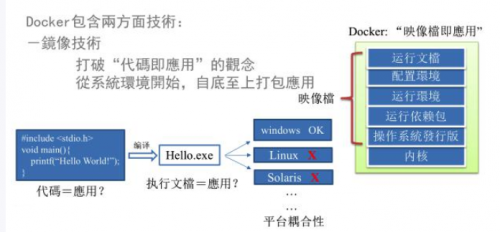
大数据分析:Docker虚拟化解析
一. 为什么会有Docker出现 一款产品从开发到上线,从操作系统,到运行环境,再到应用配置。作为开发+运维之间的协作我们需要关心很多东西,这也是很多互联网公司都不得不面对的...
查看详情 >>
-

-
大数据开发基础之WEB基本原理及常用开发工具
今天给大家带来的是大数据开发基础的WEB基本原理及常用开发工具的了解,无论是在日常生活中还是在工作办公中,我们总是会浏览到各种各样的网页,比如淘宝、微博、知乎,我们的...
查看详情 >>
-

-
大数据培训:Spark动态内存管理模式
Spark的运行机制当中,内存管理和应用是非常关键的一个环节,而在Spark 1.6之后的版本当中,动态内存管理模式上线,对于内存管理这个模块来说,也有了新变化。今天的大数据培训分享...
查看详情 >>
-

-
大数据学习:Spark静态内存管理解析
Spark采取基于内存计算的模式,很大程度上来说,对于提升计算效率的效果是显著的,但是同时也带来了对内存管理的更高要求。Spark对内存的管理,有静态和动态之分。今天的大数据学...
查看详情 >>
-

-
大数据学习:Spark Standalone模式运行机制
在Spark框架当中,最基本的Standalone模式,是学习初期最先接触到的,也是理解Spark运行机制背后的原理的重要阶段。今天的大数据学习分享,我们就主要来讲讲,Spark Standalone模式运行机...
查看详情 >>
-

-
大数据分析:关于GIT的实用技巧
一、Git diff比对命令 通常情况下,我们会在自己的独立分支中完成需求开发,此时就会有需求将自己的分支和其他分支进行对比。这个功能可以通过1git diff branch1 branch命令来实现。 如果...
查看详情 >>