大数据学习:Flink内存模型简介
作者:张老师 浏览次数: 2021-02-04 17:22
作为新一代备受关注的流计算框架,Flink受到的关注越来越多,而Flink的学习,也成为大数据框架学习的一个重要部分。今天的大数据学习分享,我们就主要来讲讲Flink内存模型的部分。

Flink在1.10之后对内存进行了升级,大大简化了内存配置,这里由浅入深,依次介绍JVM中的堆内存与堆外内存、Flink内存模型。
JVM中的堆内存与堆外内存
堆内存就是JVM本身管理的内存,一般会分成几个区域:
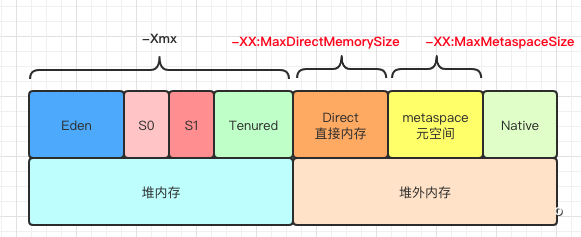
堆内存按照常见的内存模型来说,会划分成新生代和老年代,新生代划分成E区和2个存活区,新分配的对象都会在E区中申请,当内存不足时触发GC,在E区和S区之间进行一次存活拷贝,多次GC存活的对象会被转移到老年代。
在介绍堆外内存时需要先了解什么是零拷贝技术,由于操作系统的设计考虑到用户程序的安全性,会把内存分成内核空间和用户空间,用户的程序只能访问用户空间的内存。一般进行网络传输时,数据都直接存储在内核空间,因此程序想要直接使用,需要进行一次内核空间到用户空间的拷贝。
如果用户可以直接访问内核空间,就可以不进行用户空间的拷贝而直接使用,效率更高,堆外内存就提供了这种使用机制。因此在需要进行大量网络传输或数据交换时,都可以考虑使用堆外内存,比如Spark、Flink都在自己的设计中使用到了堆外内存。另外,堆外内存还可以突破JVM的限制,极大的利用物理内存资源,避免OOM(不过堆外内存仍然受限于物理内存)。
Flink的内存模型
Flink的进程同时使用到了堆内存和堆外内存:
Flink由于部署方案可以有很多种,考虑到容器化的部署方案一般需要控制容器的内存大小,因此Flink最大的内存是process内存,即进程内存。process内存中包含Flink内存和JVM内存,其中JVM内存主要是堆外内存中的元空间和执行开销,Flink内存则包含堆内存和堆外内存。一般在使用时,如果是Standalone模式一般配置Flink内存即可;如果是Yarn、K8s等,一般配置进程内存即可,两者不需要同时配置。
更细粒度的内存模型,可以直接参考官网提供的模型图片,在细节上TaskManager和JobManager还会有所不同。
其中堆内存可以通过-Xmx和-Xms来控制,堆外内存的大小可以通过-XX:MaxDirectMemorySize配置,元空间可以通过-XX:MaxMetaspaceSize配置,进程内存和flink内存可以通过相应的启动参数控制。
由于JM只需要负责Job图的解析和任务提交,因此内存模型相对TM简单很多。
堆内存划分成两部分,框架内存用于支撑Flink本身,Task内存则用于运行任务。堆外内存主要划分成托管内存和直接内存。直接内存包括框架内存、任务内存和网络缓存,其中网络缓存主要用于网络数据的buffer存储。托管内存主要用于RocksDB的状态存储和批处理算子。
关于大数据学习,Flink内存模型简介,以上就为大家做了简单的介绍了。Flink框架的流处理,在内存管理上,也是需要合理的配置的,这对于后续的运行优化也是有好处的。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及学习视频,可联系客服领取!
Flink在1.10之后对内存进行了升级,大大简化了内存配置,这里由浅入深,依次介绍JVM中的堆内存与堆外内存、Flink内存模型。
JVM中的堆内存与堆外内存
堆内存就是JVM本身管理的内存,一般会分成几个区域:
堆内存按照常见的内存模型来说,会划分成新生代和老年代,新生代划分成E区和2个存活区,新分配的对象都会在E区中申请,当内存不足时触发GC,在E区和S区之间进行一次存活拷贝,多次GC存活的对象会被转移到老年代。
在介绍堆外内存时需要先了解什么是零拷贝技术,由于操作系统的设计考虑到用户程序的安全性,会把内存分成内核空间和用户空间,用户的程序只能访问用户空间的内存。一般进行网络传输时,数据都直接存储在内核空间,因此程序想要直接使用,需要进行一次内核空间到用户空间的拷贝。
如果用户可以直接访问内核空间,就可以不进行用户空间的拷贝而直接使用,效率更高,堆外内存就提供了这种使用机制。因此在需要进行大量网络传输或数据交换时,都可以考虑使用堆外内存,比如Spark、Flink都在自己的设计中使用到了堆外内存。另外,堆外内存还可以突破JVM的限制,极大的利用物理内存资源,避免OOM(不过堆外内存仍然受限于物理内存)。
Flink的内存模型
Flink的进程同时使用到了堆内存和堆外内存:
Flink由于部署方案可以有很多种,考虑到容器化的部署方案一般需要控制容器的内存大小,因此Flink最大的内存是process内存,即进程内存。process内存中包含Flink内存和JVM内存,其中JVM内存主要是堆外内存中的元空间和执行开销,Flink内存则包含堆内存和堆外内存。一般在使用时,如果是Standalone模式一般配置Flink内存即可;如果是Yarn、K8s等,一般配置进程内存即可,两者不需要同时配置。
更细粒度的内存模型,可以直接参考官网提供的模型图片,在细节上TaskManager和JobManager还会有所不同。
其中堆内存可以通过-Xmx和-Xms来控制,堆外内存的大小可以通过-XX:MaxDirectMemorySize配置,元空间可以通过-XX:MaxMetaspaceSize配置,进程内存和flink内存可以通过相应的启动参数控制。
由于JM只需要负责Job图的解析和任务提交,因此内存模型相对TM简单很多。
堆内存划分成两部分,框架内存用于支撑Flink本身,Task内存则用于运行任务。堆外内存主要划分成托管内存和直接内存。直接内存包括框架内存、任务内存和网络缓存,其中网络缓存主要用于网络数据的buffer存储。托管内存主要用于RocksDB的状态存储和批处理算子。
关于大数据学习,Flink内存模型简介,以上就为大家做了简单的介绍了。Flink框架的流处理,在内存管理上,也是需要合理的配置的,这对于后续的运行优化也是有好处的。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及学习视频,可联系客服领取!




