-

-
大数据学习:Hive支持的常用函数总结
Hive作为Hadoop生态圈重要的支持组件之一,在具体的开发场景下,可以通过内置额函数解决大部分的需求,而Hive支持的常用函数,也是学习当中必须要掌握的。今天的大数据学习分享,我...
查看详情 >>
-

-
大数据开发-HBase拆分
我们都知道,region在数据量大到一定程度的时候,会进行拆分(最开始由一个变成二个),而拆分的方式有三种,包括预拆分、自动拆分、手动强制拆分。下面就来介绍拆分的方式,作...
查看详情 >>
-

-
大数据培训:Spark SQL读取parquet文件操作
Spark在支持大规模离线数据处理上,是极具优势性能的,而Spark框架的数据处理流程,首先就是引入数据源,其中比较常见的就是parquet文件,通过Spark SQL统一的接口去读取和写入数据。今...
查看详情 >>
-
-
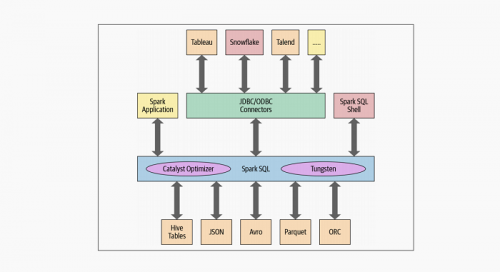
大数据学习:Spark SQL及基础引擎
Spark SQL作为Spark计算查询的重要支撑,在Spark生态当中的重要性是不言而喻的。Spark SQL使得一般的开发人员或者非专业的开发人员,也能快速完成相应的计算查询需求,这也是其存在的重...
查看详情 >>
-
-
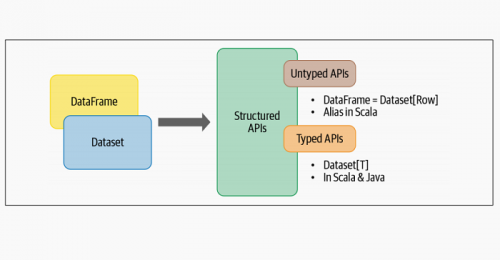
大数据学习:Spark框架Dataset API
Spark作为大数据技术生态当中必学的一个框架,其重要程度早已不用特意去强调,在现有的大数据技术生态体系当中,Spark仍然是大数据开发工程师们需要掌握的重要技能。今天的大数据...
查看详情 >>
-

-
大数据的发展现状发展如何?三个方面来看
或许你也有同样的疑问,都说大数据前景好,大数据行业发展好,那到底好在哪里?有什么依据吗? 一、环境 从大环境来说,我们从以前的互联网时代发展到了现在的大数据时代,是时...
查看详情 >>
-

-
大数据培训:HDFS Erasure Coding机制
提到大规模数据存储,Hadoop的分布式存储,作为主流的技术方案,实力也是得到市场认可的。Hadoop的分布式文件系统HDFS,其冗余备份机制,确保了数据存储的容错,但是同时也增加了冗...
查看详情 >>
-
-
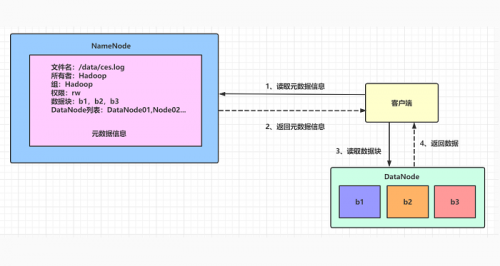
大数据学习:HDFS文件管理基础入门
HDFS作为Hadoop生态的分布式文件系统,对于底层存储来说,提供重要的支持,在学习Hadoop框架的前期,基本上都是从HDFS开始学起。今天的大数据学习分享,我们就从HDFS的入门讲起,来看...
查看详情 >>
-
-
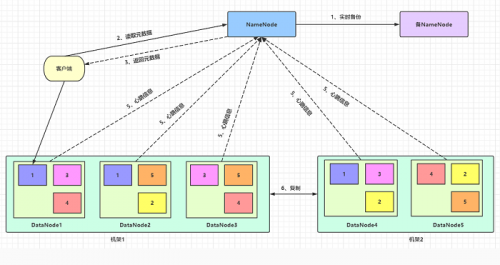
大数据学习:HDFS的容错机制
HDFS作为Hadoop的分布式文件系统,对于大批量数据的存储,要做到高效快速且不出错,一旦出错也能快速纠正,这就不得不提到HDFS的容错机制。今天的大数据学习分享,我们就来具体讲讲...
查看详情 >>






