大数据学习:Spark框架Dataset API
作者:张老师 浏览次数: 2021-05-07 16:54
Spark作为大数据技术生态当中必学的一个框架,其重要程度早已不用特意去强调,在现有的大数据技术生态体系当中,Spark仍然是大数据开发工程师们需要掌握的重要技能。今天的大数据学习分享,我们就主要来讲讲Spark框架Dataset API。
Spark2.0将DataFrame和Dataset API统一为具有类似接口的结构化API,因此开发人员只需要学习一组API。数据集具有两个特性:类型化的和非类型化的API,如下图所示。
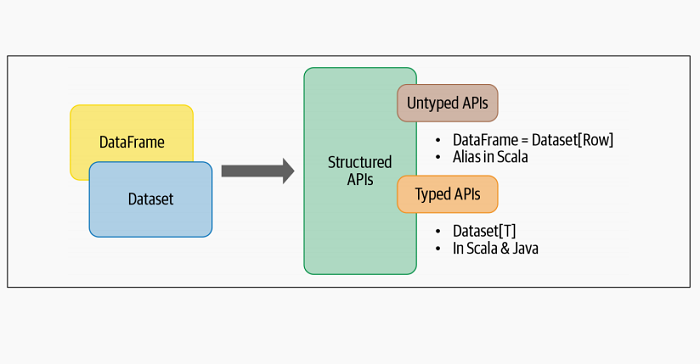
从概念上讲,我们可以将Scala中的DataFrame视为通用对象集合Dataset[Row]的别名,其中Row是通用非类型JVM对象,可能包含不同类型的字段。相比之下,Dataset是Scala中或Java中的强类型JVM对象的集合。或者,如Dataset文档所说,Dataset是:
特定域对象的强类型集合,可以使用函数或关系操作进行转换。Scala中的每个Dataset都有一个称为DataFrame的无类型视图,它是一个Dataset Row。
1、有类型的对象、非类型的对象和通用行
在Spark支持的语言中,数据集只在Java和Scala中有意义,而在Python和R中,只有DataFrame有意义。这是因为Python和R不是编译时类型安全的;类型是在执行期间动态推断或分配的,而不是在编译时动态分配的。在Scala和Java中,情况正好相反:类型在编译时绑定到变量和对象。然而,在Scala中,DataFrame只是非类型Dataset[Row]的别名。
Row是Spark中的通用对象类型,它包含可以使用索引访问的混合类型的集合。在内部,Spark会操作Row对象,并将它们转换为相应的等效类型。例如,对于Scala或Java和Python,Row中的一个整数字段将分别映射或转换为整数类型:
// In Scala
import org.apache.spark.sql.Row
val row = Row(350, true, "Learning Spark 2E", null)
# In Python
from pyspark.sql import Row
row = Row(350, True, "Learning Spark 2E", None)
使用行对象的索引,可以使用公共getter方法访问各个字段:
// In Scala
row.getInt(0)
res23: Int = 350
row.getBoolean(1)
res24: Boolean = true
row.getString(2)
res25: String = Learning Spark 2E
# In Python
row[0]
Out[13]: 350
row[1]
Out[14]: True
row[2]
Out[15]: 'Learning Spark 2E'
相比之下,类型化对象是JVM中实际的Java或Scala类对象。数据集中的每个元素都映射到一个JVM对象。
2、创建DataSet
与从数据源创建DataFrame一样,在创建数据集时,你必须知道schema。换句话说,你需要了解数据类型。尽管使用JSON和CSV数据可以推断出schema,但对于大型数据集,这是资源密集型的(成本昂贵),非常消耗资源。
在Scala中创建数据集时,为结果数据集指定schema最简单的方法是使用样例类(Case classes)。在Java中,使用JavaBean类(我们在第6章中进一步讨论JavaBean和Scala样例类)。
Scala: 样例类(Case classes)
当你希望将自己的域中特定的对象实例化为数据集时,你可以通过在Scala中定义一个样例类来实例化。作为一个例子,让我们查看JSON文件中从物联网设备读取的集合。
我们的文件有几行JSON字符串,外观如下:
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip":
"80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude":
53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21,
"humidity": 65, "battery_level": 8, "c02_level": 1408,"lcd": "red",
"timestamp" :1458081226051}
要将每个JSON条目表示为DeviceIoTData,一种特定领域的对象,我们可以定义一个Scala样例类:
case class DeviceIoTData (battery_level: Long, c02_level: Long,
cca2: String, cca3: String, cn: String, device_id: Long,
device_name: String, humidity: Long, ip: String, latitude: Double,
lcd: String, longitude: Double, scale:String, temp: Long,
timestamp: Long)
一旦定义,我们可以使用它读取文件并将返回的内容Dataset[Row]转换为Dataset[DeviceIoTData](输出被截断以适合页面):
// In Scala
val ds = spark.read
.json("/databricks-datasets/learning-spark-v2/iot-devices/iot_devices.json")
.as[DeviceIoTData]
ds: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]
ds.show(5, false)
+-------------|---------|----|----|-------------|---------|---+
|battery_level|c02_level|cca2|cca3|cn |device_id|...|
+-------------|---------|----|----|-------------|---------|---+
|8 |868 |US |USA |United States|1 |...|
|7 |1473 |NO |NOR |Norway |2 |...|
|2 |1556 |IT |ITA |Italy |3 |...|
|6 |1080 |US |USA |United States|4 |...|
|4 |931 |PH |PHL |Philippines |5 |...|
+-------------|---------|----|----|-------------|---------|---+
only showing top 5 rows
3、Dataset操作
就像你可以在DataFrame上执行转换和操作一样,你也可以使用数据集。根据操作类型的不同,操作结果将会有所不同:
// In Scala
val filterTempDS = ds.filter({d => {d.temp > 30 && d.humidity > 70})
filterTempDS: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]
filterTempDS.show(5, false)
+-------------|---------|----|----|-------------|---------|---+
|battery_level|c02_level|cca2|cca3|cn |device_id|...|
+-------------|---------|----|----|-------------|---------|---+
|0 |1466 |US |USA |United States|17 |...|
|9 |986 |FR |FRA |France |48 |...|
|8 |1436 |US |USA |United States|54 |...|
|4 |1090 |US |USA |United States|63 |...|
|4 |1072 |PH |PHL |Philippines |81 |...|
+-------------|---------|----|----|-------------|---------|---+
only showing top 5 rows
在此查询中,我们使用一个函数作为数据集方法filter()的参数。这是一个具有很多签名的重载方法。我们使用的版本采用filter(func: (T) > Boolean): Dataset[T] lambda函数func: (T) > Boolean作为参数。
lambda函数的参数是类型为DeviceIoTData的JVM对象。这样,我们可以使用点(.)表示法访问其各个数据字段,就像在Scala类或JavaBean中一样。
另一件需要注意的事情是,对于DataFrame,你将filter()条件表示为类似SQL的DSL操作,这些操作是与语言无关的。对于数据集,我们利用原生语言的表达式作为Scala或Java代码。
总的来说,我们可以在数据集上执行filter(),map(),groupBy(),select(),take()这些操作,与DataFrame上的操作相似。在某种程度上,数据集与RDD相似,因为它们提供了与上述方法类似的接口以及编译时安全性,但具有更容易读取和面向对象的编程接口。
当我们使用数据集时,底层的Spark SQL引擎会处理JVM对象的创建、控制版本、序列化和反序列化。它还借助数据集编码器来处理Java外堆内存管理。
关于大数据学习,Spark框架Dataset API,以上就为大家做了简单的介绍了。Spark在大数据学习当中,是非常重要的一块,而API编程,是必须要掌握的重要基础,建议多家练习。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!
Spark2.0将DataFrame和Dataset API统一为具有类似接口的结构化API,因此开发人员只需要学习一组API。数据集具有两个特性:类型化的和非类型化的API,如下图所示。
从概念上讲,我们可以将Scala中的DataFrame视为通用对象集合Dataset[Row]的别名,其中Row是通用非类型JVM对象,可能包含不同类型的字段。相比之下,Dataset是Scala中或Java中的强类型JVM对象的集合。或者,如Dataset文档所说,Dataset是:
特定域对象的强类型集合,可以使用函数或关系操作进行转换。Scala中的每个Dataset都有一个称为DataFrame的无类型视图,它是一个Dataset Row。
1、有类型的对象、非类型的对象和通用行
在Spark支持的语言中,数据集只在Java和Scala中有意义,而在Python和R中,只有DataFrame有意义。这是因为Python和R不是编译时类型安全的;类型是在执行期间动态推断或分配的,而不是在编译时动态分配的。在Scala和Java中,情况正好相反:类型在编译时绑定到变量和对象。然而,在Scala中,DataFrame只是非类型Dataset[Row]的别名。
Row是Spark中的通用对象类型,它包含可以使用索引访问的混合类型的集合。在内部,Spark会操作Row对象,并将它们转换为相应的等效类型。例如,对于Scala或Java和Python,Row中的一个整数字段将分别映射或转换为整数类型:
// In Scala
import org.apache.spark.sql.Row
val row = Row(350, true, "Learning Spark 2E", null)
# In Python
from pyspark.sql import Row
row = Row(350, True, "Learning Spark 2E", None)
使用行对象的索引,可以使用公共getter方法访问各个字段:
// In Scala
row.getInt(0)
res23: Int = 350
row.getBoolean(1)
res24: Boolean = true
row.getString(2)
res25: String = Learning Spark 2E
# In Python
row[0]
Out[13]: 350
row[1]
Out[14]: True
row[2]
Out[15]: 'Learning Spark 2E'
相比之下,类型化对象是JVM中实际的Java或Scala类对象。数据集中的每个元素都映射到一个JVM对象。
2、创建DataSet
与从数据源创建DataFrame一样,在创建数据集时,你必须知道schema。换句话说,你需要了解数据类型。尽管使用JSON和CSV数据可以推断出schema,但对于大型数据集,这是资源密集型的(成本昂贵),非常消耗资源。
在Scala中创建数据集时,为结果数据集指定schema最简单的方法是使用样例类(Case classes)。在Java中,使用JavaBean类(我们在第6章中进一步讨论JavaBean和Scala样例类)。
Scala: 样例类(Case classes)
当你希望将自己的域中特定的对象实例化为数据集时,你可以通过在Scala中定义一个样例类来实例化。作为一个例子,让我们查看JSON文件中从物联网设备读取的集合。
我们的文件有几行JSON字符串,外观如下:
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip":
"80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude":
53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21,
"humidity": 65, "battery_level": 8, "c02_level": 1408,"lcd": "red",
"timestamp" :1458081226051}
要将每个JSON条目表示为DeviceIoTData,一种特定领域的对象,我们可以定义一个Scala样例类:
case class DeviceIoTData (battery_level: Long, c02_level: Long,
cca2: String, cca3: String, cn: String, device_id: Long,
device_name: String, humidity: Long, ip: String, latitude: Double,
lcd: String, longitude: Double, scale:String, temp: Long,
timestamp: Long)
一旦定义,我们可以使用它读取文件并将返回的内容Dataset[Row]转换为Dataset[DeviceIoTData](输出被截断以适合页面):
// In Scala
val ds = spark.read
.json("/databricks-datasets/learning-spark-v2/iot-devices/iot_devices.json")
.as[DeviceIoTData]
ds: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]
ds.show(5, false)
+-------------|---------|----|----|-------------|---------|---+
|battery_level|c02_level|cca2|cca3|cn |device_id|...|
+-------------|---------|----|----|-------------|---------|---+
|8 |868 |US |USA |United States|1 |...|
|7 |1473 |NO |NOR |Norway |2 |...|
|2 |1556 |IT |ITA |Italy |3 |...|
|6 |1080 |US |USA |United States|4 |...|
|4 |931 |PH |PHL |Philippines |5 |...|
+-------------|---------|----|----|-------------|---------|---+
only showing top 5 rows
3、Dataset操作
就像你可以在DataFrame上执行转换和操作一样,你也可以使用数据集。根据操作类型的不同,操作结果将会有所不同:
// In Scala
val filterTempDS = ds.filter({d => {d.temp > 30 && d.humidity > 70})
filterTempDS: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]
filterTempDS.show(5, false)
+-------------|---------|----|----|-------------|---------|---+
|battery_level|c02_level|cca2|cca3|cn |device_id|...|
+-------------|---------|----|----|-------------|---------|---+
|0 |1466 |US |USA |United States|17 |...|
|9 |986 |FR |FRA |France |48 |...|
|8 |1436 |US |USA |United States|54 |...|
|4 |1090 |US |USA |United States|63 |...|
|4 |1072 |PH |PHL |Philippines |81 |...|
+-------------|---------|----|----|-------------|---------|---+
only showing top 5 rows
在此查询中,我们使用一个函数作为数据集方法filter()的参数。这是一个具有很多签名的重载方法。我们使用的版本采用filter(func: (T) > Boolean): Dataset[T] lambda函数func: (T) > Boolean作为参数。
lambda函数的参数是类型为DeviceIoTData的JVM对象。这样,我们可以使用点(.)表示法访问其各个数据字段,就像在Scala类或JavaBean中一样。
另一件需要注意的事情是,对于DataFrame,你将filter()条件表示为类似SQL的DSL操作,这些操作是与语言无关的。对于数据集,我们利用原生语言的表达式作为Scala或Java代码。
总的来说,我们可以在数据集上执行filter(),map(),groupBy(),select(),take()这些操作,与DataFrame上的操作相似。在某种程度上,数据集与RDD相似,因为它们提供了与上述方法类似的接口以及编译时安全性,但具有更容易读取和面向对象的编程接口。
当我们使用数据集时,底层的Spark SQL引擎会处理JVM对象的创建、控制版本、序列化和反序列化。它还借助数据集编码器来处理Java外堆内存管理。
关于大数据学习,Spark框架Dataset API,以上就为大家做了简单的介绍了。Spark在大数据学习当中,是非常重要的一块,而API编程,是必须要掌握的重要基础,建议多家练习。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!




