Spark高级教程:Spark核心RDD概念解析
作者:张老师 浏览次数: 2020-02-10 18:31
Spark在大数据处理上的优势,很大一部分来自数据处理速度的提升,这使得Spark在面对大规模实时计算的数据任务时,能够更快地完成大批量数据的处理,提升大数据处理的效率。而Spark获得的这些优势,核心关键在于RDD,今天我们为大家分享Spark高级教程的内容,Spark核心RDD概念解析。
所谓的RDD,全称是Resilient Distributed Datasets,翻译过来就是弹性分布式数据集,似乎念起来有点绕口,我们先从简单一点的角度来理解。
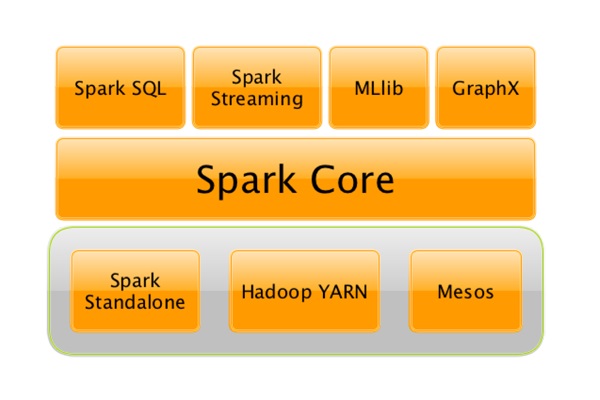
把RDD想象为一组数据,而Spark把要处理的数据、处理中间结果以及输出结果都定义成RDD,那么在Spark当中数据处理的流程就可以这样去理解——
从数据源读取数据,把输入生成一个RDD;
通过运算把输入RDD转换成另一个RDD;
再通过运算把生成的RDD转换成另一个RDD,重复需要进行的RDD转换操作(此处省略一千遍);
最后运算成结果RDD,处理结果。
经过这样一个流程,就实现了对大规模数据的处理,而Spark对于数处理,因为本身没有分布式文件系统,所以可以与Hadoop的HDFS实现协同,完成数据存储。但是Spark当中的RDD默认是在内存当中进行存储的。只有当数据量大于Spark被允许使用的内存大小时,那么可以将数据spill到磁盘上。
接下来,就是RDD的接口问题。
RDD是连接Spark数据操作的核心,接口要解决的主要问题就是,为了生成这个RDD,它的上一个RDD是谁,以及生成过程使用的运算是什么。
举个简单的例子,数据A,经过运算F,转换成了数据B,那么如果问你如何得到B,那么需要数据A+运算B,这就是接口需要提供的东西。
所以其实RDD就是一个数据集,是一组数据被处理到一个阶段的状态,在Spark当中,根据数据处理任务,会有很多个RDD,RDD彼此之间交互运算,完成最终的数据处理结果。关于Spark高级教程,RDD只是其中需要掌握的一部分,更多技术分享,可持续关注成都加米谷大数据学院!
所谓的RDD,全称是Resilient Distributed Datasets,翻译过来就是弹性分布式数据集,似乎念起来有点绕口,我们先从简单一点的角度来理解。
把RDD想象为一组数据,而Spark把要处理的数据、处理中间结果以及输出结果都定义成RDD,那么在Spark当中数据处理的流程就可以这样去理解——
从数据源读取数据,把输入生成一个RDD;
通过运算把输入RDD转换成另一个RDD;
再通过运算把生成的RDD转换成另一个RDD,重复需要进行的RDD转换操作(此处省略一千遍);
最后运算成结果RDD,处理结果。
经过这样一个流程,就实现了对大规模数据的处理,而Spark对于数处理,因为本身没有分布式文件系统,所以可以与Hadoop的HDFS实现协同,完成数据存储。但是Spark当中的RDD默认是在内存当中进行存储的。只有当数据量大于Spark被允许使用的内存大小时,那么可以将数据spill到磁盘上。
接下来,就是RDD的接口问题。
RDD是连接Spark数据操作的核心,接口要解决的主要问题就是,为了生成这个RDD,它的上一个RDD是谁,以及生成过程使用的运算是什么。
举个简单的例子,数据A,经过运算F,转换成了数据B,那么如果问你如何得到B,那么需要数据A+运算B,这就是接口需要提供的东西。
所以其实RDD就是一个数据集,是一组数据被处理到一个阶段的状态,在Spark当中,根据数据处理任务,会有很多个RDD,RDD彼此之间交互运算,完成最终的数据处理结果。关于Spark高级教程,RDD只是其中需要掌握的一部分,更多技术分享,可持续关注成都加米谷大数据学院!




