大数据学习:Apache Kafka分布式流式系统
作者:张老师 浏览次数: 2021-01-12 17:44
Kafka在大数据流式处理场景当中,正在受到越来越多的青睐,尤其在实时消息处理领域,kafka的优势是非常明显的。相比于传统的消息中间件,kafka有着更多的潜力空间。今天的大数据学习分享,我们就主要来讲讲Apache Kafka分布式流式系统。

关于Apache Kafka
本质上来说,Apache Kafka不是消息中间件的一种实现,它只是一种分布式流式系统。不同于基于队列和交换器的RabbitMQ,Kafka的存储层是使用分区事务日志来实现的。
Kafka也提供流式API用于实时的流处理以及连接器API用来更容易的和各种数据源集成。云厂商为Kafka存储层提供了可选的方案,比如Azure Event Hubsy以及AWS Kinesis Data Streams等。这些都是Kafka流处理能力受到肯定的见证。
Kafka主题
Kafka没有实现队列这种东西。相应的,Kafka按照类别存储记录集,并且把这种类别称为主题。
Kafka为每个主题维护一个消息分区日志。每个分区都是由有序的不可变的记录序列组成,并且消息都是连续的被追加在尾部。
当消息到达时,Kafka就会把他们追加到分区尾部。默认情况下,Kafka使用轮询分区器(partitioner)把消息一致的分配到多个分区上。
Kafka可以改变创建消息逻辑流的行为。例如,在一个多租户的应用中,我们可以根据每个消息中的租户ID创建消息流。
IoT场景中,我们可以在常数级别下根据生产者的身份信息(identity)将其映射到一个具体的分区上。
确保来自相同逻辑流上的消息映射到相同分区上,这就保证了消息能够按照顺序提供给消费者。
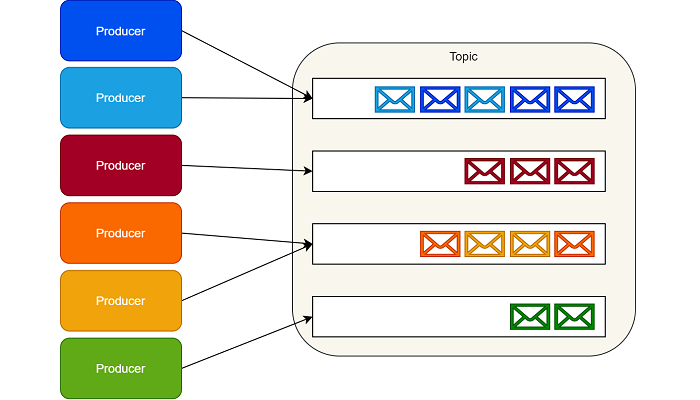
Kafka生产者
消费者通过维护分区的偏移(或者说索引)来顺序的读出消息,然后消费消息。
单个消费者可以消费多个不同的主题,并且消费者的数量可以伸缩到可获取的最大分区数量。
所以在创建主题的时候,我们要认真的考虑一下在创建的主题上预期的消息吞吐量。消费同一个主题的多个消费者构成的组称为消费者组。
通过Kafka提供的API可以处理同一消费者组中多个消费者之间的分区平衡以及消费者当前分区偏移的存储。
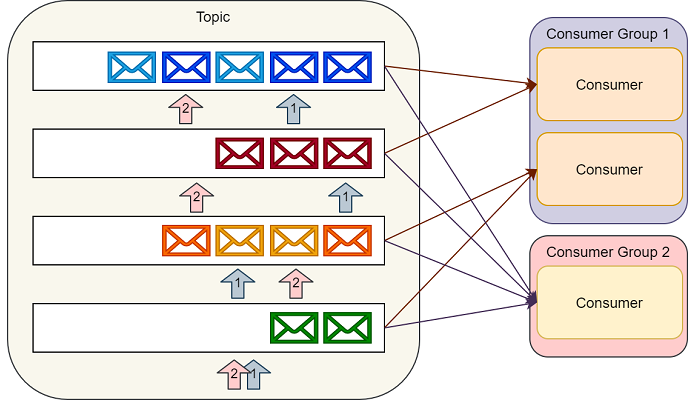
Kafka消费者
Kafka实现的消息模式
Kafka的实现很好地契合发布/订阅模式。生产者可以向一个具体的主题发送消息,然后多个消费者组可以消费相同的消息。每一个消费者组都可以独立的伸缩去处理相应的负载。
由于消费者维护自己的分区偏移,所以他们可以选择持久订阅或者临时订阅,持久订阅在重启之后不会丢失偏移而临时订阅在重启之后会丢失偏移并且每次重启之后都会从分区中最新的记录开始读取。
但是这种实现方案不能完全等价的当做典型的消息队列模式看待。当然,我们可以创建一个主题,这个主题和拥有一个消费者的消费组进行关联。这样我们就模拟出了一个典型的消息队列。
值得特别注意的是,Kafka是按照预先配置好的时间保留分区中的消息,而不是根据消费者是否消费了这些消息。
这种保留机制可以让消费者自由的重读之前的消息。另外,开发者也可以利用Kafka的存储层来实现诸如事件溯源和日志审计功能。
关于大数据学习,Apache Kafka分布式流式系统,以上就为大家做了简单的介绍了。Kafka对实时消息流的处理,尤其是大规模实时消息流的处理,是具备显著优势的,掌握Kafka在学习当中非常重要。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服获取!
关于Apache Kafka
本质上来说,Apache Kafka不是消息中间件的一种实现,它只是一种分布式流式系统。不同于基于队列和交换器的RabbitMQ,Kafka的存储层是使用分区事务日志来实现的。
Kafka也提供流式API用于实时的流处理以及连接器API用来更容易的和各种数据源集成。云厂商为Kafka存储层提供了可选的方案,比如Azure Event Hubsy以及AWS Kinesis Data Streams等。这些都是Kafka流处理能力受到肯定的见证。
Kafka主题
Kafka没有实现队列这种东西。相应的,Kafka按照类别存储记录集,并且把这种类别称为主题。
Kafka为每个主题维护一个消息分区日志。每个分区都是由有序的不可变的记录序列组成,并且消息都是连续的被追加在尾部。
当消息到达时,Kafka就会把他们追加到分区尾部。默认情况下,Kafka使用轮询分区器(partitioner)把消息一致的分配到多个分区上。
Kafka可以改变创建消息逻辑流的行为。例如,在一个多租户的应用中,我们可以根据每个消息中的租户ID创建消息流。
IoT场景中,我们可以在常数级别下根据生产者的身份信息(identity)将其映射到一个具体的分区上。
确保来自相同逻辑流上的消息映射到相同分区上,这就保证了消息能够按照顺序提供给消费者。
Kafka生产者
消费者通过维护分区的偏移(或者说索引)来顺序的读出消息,然后消费消息。
单个消费者可以消费多个不同的主题,并且消费者的数量可以伸缩到可获取的最大分区数量。
所以在创建主题的时候,我们要认真的考虑一下在创建的主题上预期的消息吞吐量。消费同一个主题的多个消费者构成的组称为消费者组。
通过Kafka提供的API可以处理同一消费者组中多个消费者之间的分区平衡以及消费者当前分区偏移的存储。
Kafka消费者
Kafka实现的消息模式
Kafka的实现很好地契合发布/订阅模式。生产者可以向一个具体的主题发送消息,然后多个消费者组可以消费相同的消息。每一个消费者组都可以独立的伸缩去处理相应的负载。
由于消费者维护自己的分区偏移,所以他们可以选择持久订阅或者临时订阅,持久订阅在重启之后不会丢失偏移而临时订阅在重启之后会丢失偏移并且每次重启之后都会从分区中最新的记录开始读取。
但是这种实现方案不能完全等价的当做典型的消息队列模式看待。当然,我们可以创建一个主题,这个主题和拥有一个消费者的消费组进行关联。这样我们就模拟出了一个典型的消息队列。
值得特别注意的是,Kafka是按照预先配置好的时间保留分区中的消息,而不是根据消费者是否消费了这些消息。
这种保留机制可以让消费者自由的重读之前的消息。另外,开发者也可以利用Kafka的存储层来实现诸如事件溯源和日志审计功能。
关于大数据学习,Apache Kafka分布式流式系统,以上就为大家做了简单的介绍了。Kafka对实时消息流的处理,尤其是大规模实时消息流的处理,是具备显著优势的,掌握Kafka在学习当中非常重要。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服获取!




