大数据学习:HBase刷写与合并机制介绍
作者:张老师 浏览次数: 2021-01-12 17:40
大数据技术生态当中,NoSQL数据库是数据存储的重要支持,而提到NoSQL数据库,Hbase一定是不可忽视的一个。Hbase源自Google Big Table,与Hadoop生态联系紧密,也是学习当中的重点。今天的大数据学习分享,我们就主要来讲讲,HBase刷写与合并机制介绍。

HBase作为主流的NoSQL数据库之一,主打高可靠、高性能、高伸缩的分布式KV存储系统,而构成高可靠、高性能、高伸缩的存储系统,与HBase的核心机制,刷写(Flush)和合并(Compaction)紧密相关。
1、为什么要进行刷写和合并
HBase底层存储引擎是基于LSM树(Log-Structured Merge Tree)数据结构设计的。写入数据时会先写WAL日志,再将数据写到写缓存MemStore中,等写缓存达到一定规模或其他触发条件时会Flush刷写到磁盘,生成一个HFile文件,这样就将磁盘随机写变成了顺序写,提高了写性能。基本拓扑图如下:
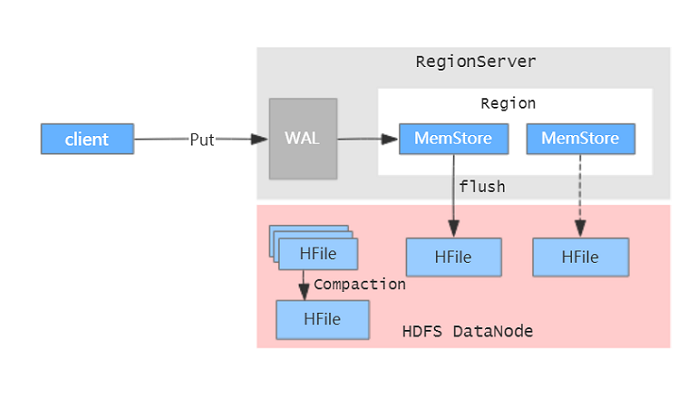
随着时间推移,写入的HFile会越来越多,读取数据时就会因为要进行多次IO导致性能降低,因此HBase会定期执行Compaction操作以合并减少HFile数量,提升读性能。
2、Flush触发条件
Flush的触发条件大致可以分为以下几类:
①当一个MemStore大小达到阈值hbase.hregion.memstore.flush.size(默认128M)时,会触发MemStore的刷写。这个时候不会阻塞写请求。
②当一个Region中所有MemStore总大小达到hbase.hregion.memstore.block.multiplier*hbase.hregion.memstore.flush.size(默认4*128M=512M)时,会触发MemStore的刷写,并阻塞Region所有的写请求,此时写数据会出现RegionTooBusyException异常。
③当一个RegionServer中所有MemStore总大小达到hbase.regionserver.global.memstore.size.lower.limit*hbase.regionserver.global.memstore.size*hbase_heapsize(低水位阈值,默认0.95*0.4*RS堆大小)时,会触发RegionServer中内存占用大的MemStore的刷写;达到hbase.regionserver.global.memstore.size*hbase_heapsize(高水位阈值,默认0.4*RS堆大小)时,不仅会触发Memstore的刷写,还会阻塞RegionServer所有的写请求,直到Memstore总大小降到低水位阈值以下。
④当一个RegionServer的HLog即WAL文件数量达到上限(可通过参数hbase.regionserver.maxlogs配置,默认32)时,也会触发MemStore的刷写,HBase会找到最旧的HLog文件对应的Region进行刷写。
⑤当一个Region的更新次数达到hbase.regionserver.flush.per.changes(默认30000000即3千万)时,也会触发MemStore的刷写。
⑥定期hbase.regionserver.optionalcacheflushinterval(默认3600000即一个小时)进行MemStore的刷写,确保MemStore不会长时间没有持久化。为避免所有的MemStore在同一时间进行flush而导致问题,定期的flush操作会有一定时间的随机延时。
⑦手动执行flush操作,我们可以通过hbase shell或API对一张表或一个Region进行flush。
3、Compaction类型、触发时机
HBase定期执行Compaction合并HFile,提升读性能,其实就是以短时间内的IO消耗,换取相对稳定的读取性能。
Compaction类型
Compaction分为两种:Minor Compaction与Major Compaction,可以称为小合并、大合并,简单示意图如下:
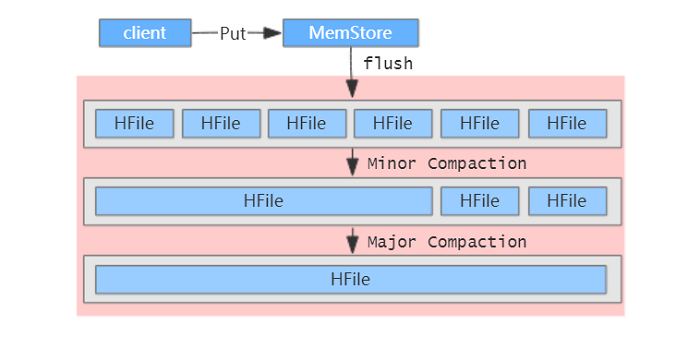
Minor Compaction是指选取一些小的、相邻的HFile将他们合并成一个更大的HFile。默认情况下,Minor Compaction会删除选取HFile中的TTL过期数据。
Major Compaction是指将一个Store中所有的HFile合并成一个HFile,这个过程会清理三类没有意义的数据:被删除的数据(打了Delete标记的数据)、TTL过期数据、版本号超过设定版本号的数据。
另外,一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此,生产环境下通常关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
Compaction触发时机
概括的说,HBase会在三种情况下检查是否要触发Compaction,分别是MemStore Flush、后台线程周期性检查、手动触发。
MemStore Flush:Compaction的根源就在于Flush,MemStore达到一定阈值或触发条件就会执行Flush操作,在磁盘上生成HFile文件,正是因为HFile文件越来越多才需要Compact。HBase每次Flush之后,都会判断是否要进行Compaction,一旦满足Minor Compaction或Major Compaction的条件便会触发执行。
后台线程周期性检查:后台线程CompactionChecker会定期检查是否需要执行Compaction,检查周期为hbase.server.thread.wakefrequency*hbase.server.compactchecker.interval.multiplier,这里主要考虑的是一段时间内没有写入仍然需要做Compact检查。
其中参数hbase.server.thread.wakefrequency默认值10000即10s,是HBase服务端线程唤醒时间间隔,用于LogRoller、MemStoreFlusher等的周期性检查;参数hbase.server.compactchecker.interval.multiplier默认值1000,是Compaction操作周期性检查乘数因子,10*1000 s时间上约等于2hrs,46mins,40sec。
手动触发:通过HBase Shell、Master UI界面或HBase API等任一种方式执行compact、major_compact等命令,会立即触发Compaction。
关于大数据学习,HBase刷写与合并机制介绍,以上就为大家做了简单的介绍了。Hbase基于分布式架构进行存储,刷写和合并机制是非常重要的内部机制,建议要深入理解和掌握。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服获取!
HBase作为主流的NoSQL数据库之一,主打高可靠、高性能、高伸缩的分布式KV存储系统,而构成高可靠、高性能、高伸缩的存储系统,与HBase的核心机制,刷写(Flush)和合并(Compaction)紧密相关。
1、为什么要进行刷写和合并
HBase底层存储引擎是基于LSM树(Log-Structured Merge Tree)数据结构设计的。写入数据时会先写WAL日志,再将数据写到写缓存MemStore中,等写缓存达到一定规模或其他触发条件时会Flush刷写到磁盘,生成一个HFile文件,这样就将磁盘随机写变成了顺序写,提高了写性能。基本拓扑图如下:
随着时间推移,写入的HFile会越来越多,读取数据时就会因为要进行多次IO导致性能降低,因此HBase会定期执行Compaction操作以合并减少HFile数量,提升读性能。
2、Flush触发条件
Flush的触发条件大致可以分为以下几类:
①当一个MemStore大小达到阈值hbase.hregion.memstore.flush.size(默认128M)时,会触发MemStore的刷写。这个时候不会阻塞写请求。
②当一个Region中所有MemStore总大小达到hbase.hregion.memstore.block.multiplier*hbase.hregion.memstore.flush.size(默认4*128M=512M)时,会触发MemStore的刷写,并阻塞Region所有的写请求,此时写数据会出现RegionTooBusyException异常。
③当一个RegionServer中所有MemStore总大小达到hbase.regionserver.global.memstore.size.lower.limit*hbase.regionserver.global.memstore.size*hbase_heapsize(低水位阈值,默认0.95*0.4*RS堆大小)时,会触发RegionServer中内存占用大的MemStore的刷写;达到hbase.regionserver.global.memstore.size*hbase_heapsize(高水位阈值,默认0.4*RS堆大小)时,不仅会触发Memstore的刷写,还会阻塞RegionServer所有的写请求,直到Memstore总大小降到低水位阈值以下。
④当一个RegionServer的HLog即WAL文件数量达到上限(可通过参数hbase.regionserver.maxlogs配置,默认32)时,也会触发MemStore的刷写,HBase会找到最旧的HLog文件对应的Region进行刷写。
⑤当一个Region的更新次数达到hbase.regionserver.flush.per.changes(默认30000000即3千万)时,也会触发MemStore的刷写。
⑥定期hbase.regionserver.optionalcacheflushinterval(默认3600000即一个小时)进行MemStore的刷写,确保MemStore不会长时间没有持久化。为避免所有的MemStore在同一时间进行flush而导致问题,定期的flush操作会有一定时间的随机延时。
⑦手动执行flush操作,我们可以通过hbase shell或API对一张表或一个Region进行flush。
3、Compaction类型、触发时机
HBase定期执行Compaction合并HFile,提升读性能,其实就是以短时间内的IO消耗,换取相对稳定的读取性能。
Compaction类型
Compaction分为两种:Minor Compaction与Major Compaction,可以称为小合并、大合并,简单示意图如下:
Minor Compaction是指选取一些小的、相邻的HFile将他们合并成一个更大的HFile。默认情况下,Minor Compaction会删除选取HFile中的TTL过期数据。
Major Compaction是指将一个Store中所有的HFile合并成一个HFile,这个过程会清理三类没有意义的数据:被删除的数据(打了Delete标记的数据)、TTL过期数据、版本号超过设定版本号的数据。
另外,一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此,生产环境下通常关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
Compaction触发时机
概括的说,HBase会在三种情况下检查是否要触发Compaction,分别是MemStore Flush、后台线程周期性检查、手动触发。
MemStore Flush:Compaction的根源就在于Flush,MemStore达到一定阈值或触发条件就会执行Flush操作,在磁盘上生成HFile文件,正是因为HFile文件越来越多才需要Compact。HBase每次Flush之后,都会判断是否要进行Compaction,一旦满足Minor Compaction或Major Compaction的条件便会触发执行。
后台线程周期性检查:后台线程CompactionChecker会定期检查是否需要执行Compaction,检查周期为hbase.server.thread.wakefrequency*hbase.server.compactchecker.interval.multiplier,这里主要考虑的是一段时间内没有写入仍然需要做Compact检查。
其中参数hbase.server.thread.wakefrequency默认值10000即10s,是HBase服务端线程唤醒时间间隔,用于LogRoller、MemStoreFlusher等的周期性检查;参数hbase.server.compactchecker.interval.multiplier默认值1000,是Compaction操作周期性检查乘数因子,10*1000 s时间上约等于2hrs,46mins,40sec。
手动触发:通过HBase Shell、Master UI界面或HBase API等任一种方式执行compact、major_compact等命令,会立即触发Compaction。
关于大数据学习,HBase刷写与合并机制介绍,以上就为大家做了简单的介绍了。Hbase基于分布式架构进行存储,刷写和合并机制是非常重要的内部机制,建议要深入理解和掌握。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服获取!




