大数据学习:HBase的Region分裂策略及过程
作者:张老师 浏览次数: 2021-07-26 17:24
Hbase当中一个重要的概念,就是基于Region的分区问题,其中包括分裂和合并两个部分,一般来说,分裂的使用会多一些,合并的场景比较有限,但也需要了解。今天的大数据学习分享,我们主要俩讲讲HBase的Region分裂策略及过程。

一般来说,当HBase中空闲Region较多时,便会进行Region合并,以减少空闲Region的个数。同时,当HBase中的单个Region满足分裂策略时,便会进行分裂。Region分裂或者Region合并,都是基于提高HBase的性能出发的。
Region分裂流程如下图:
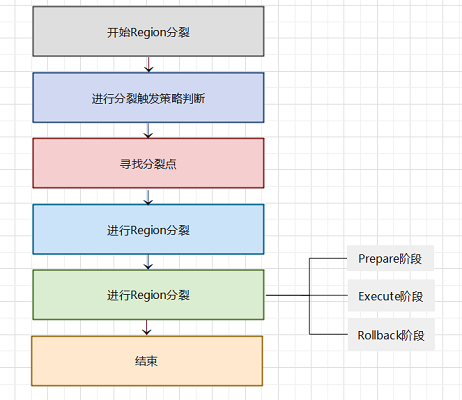
Region分裂策略
HBase中常见的分裂触发策略有以下三种:ConstantSizeSplitPolicy,IncreasingToUpperBoundRegionSplitPolicy,SteppingSplitPolicy。
ConstantSizeSplitPolicy:HBase在0.94版本之前默认使用该分裂策略,当一个Region中最大Store的大小超过设置的阈值,该阈值通过hbase.hregion.max.filesize设置。便会触发分裂。
优点:在三种策略中最简单。
缺点:分裂策略对大表和小表没有明显的区分。如果阈值设置较大,对大表比较友好,但是小表不会触发分裂,如果设置较小,对于小表友好,但对大表会造成产生大量Region的问题。
IncreasingToUpperBoundRegionSplitPolicy:在0.94版本~2.0版本默认使用该分裂策略。该策略与ConstantSizeRegionSplitPolicy思路类似,一个Region中最大Store大小超过设置阈值就会触发分裂。与ConstantSizeRegionSplitPolicy不同的是,该策略中阈值是一个变化值,在一定条件下不断调整,阈值的值为(#regions)*(#regions)*(#regions)*flushsize*2,但是阈值不会无限增大,最大值为设置的MaxRegionFileSize。
优点:弥补了ConstantSizeRegionSplitPolicy的短板,能够自适应大表和小表,对集群规模较大的场景下对大表友好。
缺点:在大集群场景下,很多小表会产生大量小Region。
SteppingSplitPolicy:2.0版本默认使用该分裂策略。分裂阈值大小和待分裂Region所属表在当前RegionServer上的Region个数相关。如果Region个数等于1,分裂阈值为flushsize*2,否则为MaxRegionFileSIze。
优点:对大集群中的大表,小表比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小Region。
除了这三种常见策略还有一些其他策略,一般使用默认方式即可,也可根据需要进行学习。
Region的分裂点
分裂点的定义:整个Region中最大Store中的最大文件中最中心的一个Block的首个rowkey,如果定位到的rowkey是整个文件的首个rowkey或者最后rowkey,则认为没有分裂点。
常见的没有分裂点的场景为:待分裂Region只有一个Block,执行split的时候会无法分裂。
Region分裂过程
Region分裂整体被分为一个事务,保证了分裂事务的原子性,总共分为三个阶段,prepare,execute和rollback。
prepare阶段:
HBase在内存中初始化两个子Region,会生成两个HRegionInfo对象,包含tableName,RegionName,startkey,endkey,还会生成一个transaction journal,记录分裂的进展。
execute阶段,该阶段可以详细分为以下几个步骤:
1)RegionServer与ZooKeeper交互,更改ZooKeeper节点下/region-in-transaction中Region的状态为SPLITING。
2)HMaster与ZooKeeper交互,通过检测ZooKeeper中/region-in-transaction下的Region状态,修改内存中Region的状态,在HMaster的Web UI页面可以看到Region执行Split的状态信息。
3)在父存储目录下建立临时文件夹.split,保存split后的daughter region信息。
4)关闭父Region,父Region关闭数据写入并触发flush操作,将写入Region的数据持久化到磁盘。此后一段时间客户端的请求会抛出异常NotServingRegionException。
5)在.split文件夹下新建两个子文件夹,称为daughter A与daughter B。在文件夹中生成reference文件,指向父Region中对应文件。reference文件名为父region对应的HFile文件.父Region。
6)父Region分裂为两个子Region后,将daguhter A与daughter B拷贝到HBase根目录下,形成两个新的Region。
7)父Region通知修改hbase:meta表后下线,不再提供服务,下线后父Region在meta表中的信息不会马上删除,而是将split和offline列标注为true。并记录两个子Region。
8)开启daughter A,daughter B两个子Region,修改hbase:meta表,正式对外提供服务。
rollback阶段:如果execute阶段出现异常,则会执行rollback操作。回滚过程中,会删除ZooKeeper中的拆分节点,清理父Region下的拆分目录,重新对父Region执行初始化操作并上线,然后清理子Region的存储目录,关闭子Region。
关于大数据学习,HBase的Region分裂策略及过程,以上就为大家做了相应的介绍了。Hbase的Region分裂与合并,其实都是基于提升效率来的,掌握基本的策略还是非常有必要的。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!
一般来说,当HBase中空闲Region较多时,便会进行Region合并,以减少空闲Region的个数。同时,当HBase中的单个Region满足分裂策略时,便会进行分裂。Region分裂或者Region合并,都是基于提高HBase的性能出发的。
Region分裂流程如下图:
Region分裂策略
HBase中常见的分裂触发策略有以下三种:ConstantSizeSplitPolicy,IncreasingToUpperBoundRegionSplitPolicy,SteppingSplitPolicy。
ConstantSizeSplitPolicy:HBase在0.94版本之前默认使用该分裂策略,当一个Region中最大Store的大小超过设置的阈值,该阈值通过hbase.hregion.max.filesize设置。便会触发分裂。
优点:在三种策略中最简单。
缺点:分裂策略对大表和小表没有明显的区分。如果阈值设置较大,对大表比较友好,但是小表不会触发分裂,如果设置较小,对于小表友好,但对大表会造成产生大量Region的问题。
IncreasingToUpperBoundRegionSplitPolicy:在0.94版本~2.0版本默认使用该分裂策略。该策略与ConstantSizeRegionSplitPolicy思路类似,一个Region中最大Store大小超过设置阈值就会触发分裂。与ConstantSizeRegionSplitPolicy不同的是,该策略中阈值是一个变化值,在一定条件下不断调整,阈值的值为(#regions)*(#regions)*(#regions)*flushsize*2,但是阈值不会无限增大,最大值为设置的MaxRegionFileSize。
优点:弥补了ConstantSizeRegionSplitPolicy的短板,能够自适应大表和小表,对集群规模较大的场景下对大表友好。
缺点:在大集群场景下,很多小表会产生大量小Region。
SteppingSplitPolicy:2.0版本默认使用该分裂策略。分裂阈值大小和待分裂Region所属表在当前RegionServer上的Region个数相关。如果Region个数等于1,分裂阈值为flushsize*2,否则为MaxRegionFileSIze。
优点:对大集群中的大表,小表比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小Region。
除了这三种常见策略还有一些其他策略,一般使用默认方式即可,也可根据需要进行学习。
Region的分裂点
分裂点的定义:整个Region中最大Store中的最大文件中最中心的一个Block的首个rowkey,如果定位到的rowkey是整个文件的首个rowkey或者最后rowkey,则认为没有分裂点。
常见的没有分裂点的场景为:待分裂Region只有一个Block,执行split的时候会无法分裂。
Region分裂过程
Region分裂整体被分为一个事务,保证了分裂事务的原子性,总共分为三个阶段,prepare,execute和rollback。
prepare阶段:
HBase在内存中初始化两个子Region,会生成两个HRegionInfo对象,包含tableName,RegionName,startkey,endkey,还会生成一个transaction journal,记录分裂的进展。
execute阶段,该阶段可以详细分为以下几个步骤:
1)RegionServer与ZooKeeper交互,更改ZooKeeper节点下/region-in-transaction中Region的状态为SPLITING。
2)HMaster与ZooKeeper交互,通过检测ZooKeeper中/region-in-transaction下的Region状态,修改内存中Region的状态,在HMaster的Web UI页面可以看到Region执行Split的状态信息。
3)在父存储目录下建立临时文件夹.split,保存split后的daughter region信息。
4)关闭父Region,父Region关闭数据写入并触发flush操作,将写入Region的数据持久化到磁盘。此后一段时间客户端的请求会抛出异常NotServingRegionException。
5)在.split文件夹下新建两个子文件夹,称为daughter A与daughter B。在文件夹中生成reference文件,指向父Region中对应文件。reference文件名为父region对应的HFile文件.父Region。
6)父Region分裂为两个子Region后,将daguhter A与daughter B拷贝到HBase根目录下,形成两个新的Region。
7)父Region通知修改hbase:meta表后下线,不再提供服务,下线后父Region在meta表中的信息不会马上删除,而是将split和offline列标注为true。并记录两个子Region。
8)开启daughter A,daughter B两个子Region,修改hbase:meta表,正式对外提供服务。
rollback阶段:如果execute阶段出现异常,则会执行rollback操作。回滚过程中,会删除ZooKeeper中的拆分节点,清理父Region下的拆分目录,重新对父Region执行初始化操作并上线,然后清理子Region的存储目录,关闭子Region。
关于大数据学习,HBase的Region分裂策略及过程,以上就为大家做了相应的介绍了。Hbase的Region分裂与合并,其实都是基于提升效率来的,掌握基本的策略还是非常有必要的。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!




