大数据学习:数据仓库建模方法与模型
作者:张老师 浏览次数: 2021-01-26 17:35
大数据平台当中的数据仓库,往往需要通过建模来更好地对数据进行存储和管理,这其中涉及到性能、成本、效率、质量等多方面的综合考量,对于工程师来说,也需要细细规划。今天的大数据学习分享,我们主要来讲讲数据仓库建模方法与模型。

数仓建模方法
数据仓库中几种经典的数据模型,包括关系建模、维度建模、DataVault模型。在实际工作中,通常会根据业务场景选择一种或几种模型。
1、关系建模
关系建模,是数据仓库之父Inmon推崇的,被称为“实体-关系”模型,以一种“标准化”的方式存在,强调数据之间非冗余,满足3NF。关系建模是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系抽象。它更多用于数据的整合和一致性质量。
2、维度建模
维度建模,Ralph Kimball博士最先提出这一概念。其最简单的描述就是,按照事实表、维表来构建数据仓库、数据集市。这种方法很多人称之为星形模型。之所以称为星形模型是因为它的表示方法是以一颗“星”为中心,周围围绕着其他数据结构,如下图。
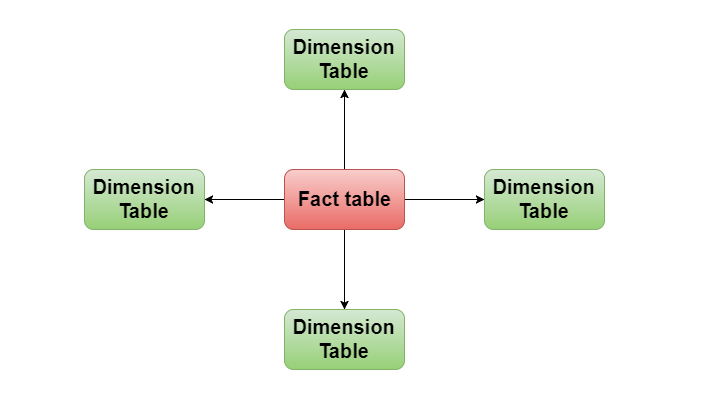
星形模型的中心是一张事实表。事实表是包含大量数据值的一种结构。事实表的周围是维表,用来描述事实表的某个重要方面。维表里的数据量要比事实表里的少。
星形模型之所以广泛被使用,在于针对各个维作了大量的预处理,比如按照维进行了预先的排序、分类、统计等。通过这些预处理,能够极大地提升数据仓库的处理能力。特别是针对3NF的建模方法,星形模型在性能上占据明显的优势。因此,星形模型仅适用于小范围数据(如一个部门或甚至一个子部门)。
通常星形模型只包含一张事实表。但是在数据库设计中要创建一种雪花结构的复合结构,需要多张事实表结合。如下图,描绘了一个雪花模型。

在雪花模型中,不同的事实表通过共享一个或多个公共维表连接起来。有时称这些共享的维表为一致维表。
维度建模的最大优点在于访问的高效性。如果设计适当,通过星形连接将数据传递给最终用户是非常高效的。为了提高传递信息的效率,必须收集并吸收最终用户的请求。最终用户使用数据的过程是要定义什么样的多维结构的核心。一旦清楚了最终用户的请求,这些请求就可以用来最终确定星形模型,形成最理想的结构。
3、Data Vault模型
Data Vault是另一种数据仓库建模方法,是Dan Linstedt在20世纪90年代提出的,主要用于企业级的数据仓库建模。
Data Vault需要跟踪所有数据的来源,因此其中每个数据行都要包含数据来源和装载时间属性,用以审计和跟踪数据值对应的源系统。
Data Vault不区分数据在业务层面的正确与错误,它保留操作型系统的所有时间的所有数据,装载数据时不做数据验证、清洗等工作,这点明显有别于其他数据仓库建模方法。
Data Vault是对ER模型更近一步的规范化,由于对数据的拆解更偏向于基础数据组织,在处理分析类场景时相对复杂,适合数据仓库底层构建,目前实际应用场景较少。
关于大数据学习,数据仓库建模方法与模型,以上就为大家做了简单的介绍了。数据仓库建模,是数仓设计当中的重要阶段,根据实际的应用需求,选择合适的方法与模型,是工程师必备的能力之一。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析挖掘,零基础班本月正在招生中,课程大纲及学习视频可联系客服领取!
数仓建模方法
数据仓库中几种经典的数据模型,包括关系建模、维度建模、DataVault模型。在实际工作中,通常会根据业务场景选择一种或几种模型。
1、关系建模
关系建模,是数据仓库之父Inmon推崇的,被称为“实体-关系”模型,以一种“标准化”的方式存在,强调数据之间非冗余,满足3NF。关系建模是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系抽象。它更多用于数据的整合和一致性质量。
2、维度建模
维度建模,Ralph Kimball博士最先提出这一概念。其最简单的描述就是,按照事实表、维表来构建数据仓库、数据集市。这种方法很多人称之为星形模型。之所以称为星形模型是因为它的表示方法是以一颗“星”为中心,周围围绕着其他数据结构,如下图。
星形模型的中心是一张事实表。事实表是包含大量数据值的一种结构。事实表的周围是维表,用来描述事实表的某个重要方面。维表里的数据量要比事实表里的少。
星形模型之所以广泛被使用,在于针对各个维作了大量的预处理,比如按照维进行了预先的排序、分类、统计等。通过这些预处理,能够极大地提升数据仓库的处理能力。特别是针对3NF的建模方法,星形模型在性能上占据明显的优势。因此,星形模型仅适用于小范围数据(如一个部门或甚至一个子部门)。
通常星形模型只包含一张事实表。但是在数据库设计中要创建一种雪花结构的复合结构,需要多张事实表结合。如下图,描绘了一个雪花模型。
在雪花模型中,不同的事实表通过共享一个或多个公共维表连接起来。有时称这些共享的维表为一致维表。
维度建模的最大优点在于访问的高效性。如果设计适当,通过星形连接将数据传递给最终用户是非常高效的。为了提高传递信息的效率,必须收集并吸收最终用户的请求。最终用户使用数据的过程是要定义什么样的多维结构的核心。一旦清楚了最终用户的请求,这些请求就可以用来最终确定星形模型,形成最理想的结构。
3、Data Vault模型
Data Vault是另一种数据仓库建模方法,是Dan Linstedt在20世纪90年代提出的,主要用于企业级的数据仓库建模。
Data Vault需要跟踪所有数据的来源,因此其中每个数据行都要包含数据来源和装载时间属性,用以审计和跟踪数据值对应的源系统。
Data Vault不区分数据在业务层面的正确与错误,它保留操作型系统的所有时间的所有数据,装载数据时不做数据验证、清洗等工作,这点明显有别于其他数据仓库建模方法。
Data Vault是对ER模型更近一步的规范化,由于对数据的拆解更偏向于基础数据组织,在处理分析类场景时相对复杂,适合数据仓库底层构建,目前实际应用场景较少。
关于大数据学习,数据仓库建模方法与模型,以上就为大家做了简单的介绍了。数据仓库建模,是数仓设计当中的重要阶段,根据实际的应用需求,选择合适的方法与模型,是工程师必备的能力之一。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析挖掘,零基础班本月正在招生中,课程大纲及学习视频可联系客服领取!
- 上一篇:大数据学习:数据仓库分层设计
- 下一篇:大数据培训:ETL入门简介




