大数据学习:Hadoop HDFS核心角色及作用
作者:张老师 浏览次数: 2021-06-08 17:02
作为Hadoop的三大核心之一,HDFS的重要性不言而喻,在底层存储上,要快速完成大规模数据的分布式存储任务,HDFS不可或缺。今天的大数据学习分享,我们来讲讲HDFS当中的几大核心角色,及其在架构层面所承担的工作任务。
HDFS作为典型的master/slave架构。HDFS集群由单个Namenode组成,Namenode管理文件系统名称空间并控制客户机对文件的访问。此外,还有许多datanode,通常是集群中每个节点一个,它们管理连接到运行它们的节点的存储。在HDFS内部,文件被分割成一个或多个块,这些块存储在一组datanode中。Namenode执行文件系统命名空间操作,如打开、关闭和重命名文件和目录。它还确定块到数据节点的映射。datanode负责提供来自文件系统客户机的读写请求。datanode还根据来自名称节点的指令执行块创建、删除和复制。
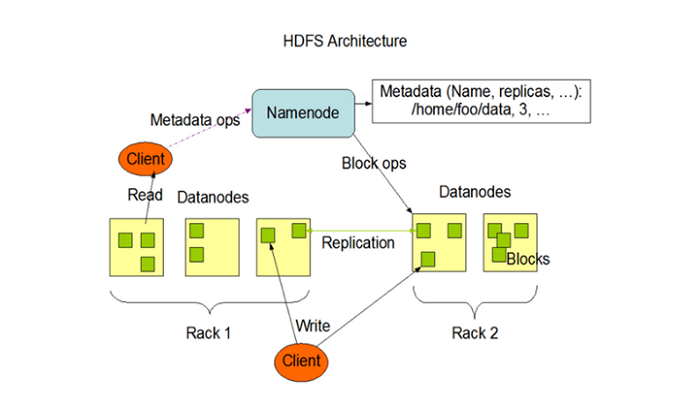
HDFS核心角色
HDFS核心角色包括Namenode、secondary node、datanode、client。
一、Namenode
Namenode的作用相当于文件系统管理者,管理、调度整个分布式文件系统,是一个老大哥的角色,它具体的作用:
1.管理HDFS的命名空间。我们上传的文件,文件的名字以及文件具体存储在集群中那台机器中,都是需要通过Namenode来完成的。
2.配置副本策略。HDFS文件系统的优点之一就是可靠性,而这个可靠性的来源就是对一份文件会自动保存多个副本,而每份文件保存多少个副本,每个副本有存储在哪个DataNode节点中,是依靠Namenode来管理。
3.管理数据块(Block)映射信息。上传一份文件,会被切割分成几块上传存储。而最后要读取整个文件就需要记录每个文件块的顺序和存储位置才可以形成最后的完整文件,这些信息就是存储在Block中。
4.处理客户端的读取和写入请求。我们在向HDFS中上传文件或者读取文件都是向Namenode发送请求,由它来处理我们的请求。
二、DataNode
就是Slave,相当于干活的打工者,由Namenode调度派发工作,具体作用有:
1.存储实际的数据块,Namenode负责文件的名字等信息,然后支配那几个DataNode来存储。
2.执行数据块的读写操作,客户端在和Namenode请求完成后,Namenode会确定那几个DataNode来完成客户端(Client)的请求。
三、secondary Namenode
它并不是Namenode的热备,相当于Namenode的助理。具体作用有:
1.辅助Namenode,分担其工作量,如定期合并Fsimage和Edits,并推送给Namenode;
2.如果Namenode突然出现问题,可以辅助Namenode回复。
四、Client
Client是客户端,具体作用有:
1.文件由Namenode负责记录文件块的信息,而文件的切分工作是由HDFS来完成。
2.和Namenode交互,获取文件的位置信息;
3.DataNode交互,当从Namenode处获得到文件的存储位置后就会和DataNode建立连接,完成文件的上传和读取;
4.client中会有一些命令来访问HDFS,如:对HDFS中文件的增删改查;
其实,HDFS中的这四种角色实际就是几个java进程,也就是相当于几个应用程序,通常Namenode、DataNode、secondaryNode是运行在linux系统中的进程,最后文件的存储还是需要物理磁盘完成,HDFS相当于对文件的管理,负责对文件备份、切分等内容。
关于大数据学习,Hadoop HDFS核心角色及作用,以上就为大家做了大致的介绍了。HDFS作为分布式文件系统来说,其在大数据技术生态当中的地位不必特意强调,学习阶段要掌握扎实。成都加米谷大数据,专业大数据培训,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!
HDFS作为典型的master/slave架构。HDFS集群由单个Namenode组成,Namenode管理文件系统名称空间并控制客户机对文件的访问。此外,还有许多datanode,通常是集群中每个节点一个,它们管理连接到运行它们的节点的存储。在HDFS内部,文件被分割成一个或多个块,这些块存储在一组datanode中。Namenode执行文件系统命名空间操作,如打开、关闭和重命名文件和目录。它还确定块到数据节点的映射。datanode负责提供来自文件系统客户机的读写请求。datanode还根据来自名称节点的指令执行块创建、删除和复制。
HDFS核心角色
HDFS核心角色包括Namenode、secondary node、datanode、client。
一、Namenode
Namenode的作用相当于文件系统管理者,管理、调度整个分布式文件系统,是一个老大哥的角色,它具体的作用:
1.管理HDFS的命名空间。我们上传的文件,文件的名字以及文件具体存储在集群中那台机器中,都是需要通过Namenode来完成的。
2.配置副本策略。HDFS文件系统的优点之一就是可靠性,而这个可靠性的来源就是对一份文件会自动保存多个副本,而每份文件保存多少个副本,每个副本有存储在哪个DataNode节点中,是依靠Namenode来管理。
3.管理数据块(Block)映射信息。上传一份文件,会被切割分成几块上传存储。而最后要读取整个文件就需要记录每个文件块的顺序和存储位置才可以形成最后的完整文件,这些信息就是存储在Block中。
4.处理客户端的读取和写入请求。我们在向HDFS中上传文件或者读取文件都是向Namenode发送请求,由它来处理我们的请求。
二、DataNode
就是Slave,相当于干活的打工者,由Namenode调度派发工作,具体作用有:
1.存储实际的数据块,Namenode负责文件的名字等信息,然后支配那几个DataNode来存储。
2.执行数据块的读写操作,客户端在和Namenode请求完成后,Namenode会确定那几个DataNode来完成客户端(Client)的请求。
三、secondary Namenode
它并不是Namenode的热备,相当于Namenode的助理。具体作用有:
1.辅助Namenode,分担其工作量,如定期合并Fsimage和Edits,并推送给Namenode;
2.如果Namenode突然出现问题,可以辅助Namenode回复。
四、Client
Client是客户端,具体作用有:
1.文件由Namenode负责记录文件块的信息,而文件的切分工作是由HDFS来完成。
2.和Namenode交互,获取文件的位置信息;
3.DataNode交互,当从Namenode处获得到文件的存储位置后就会和DataNode建立连接,完成文件的上传和读取;
4.client中会有一些命令来访问HDFS,如:对HDFS中文件的增删改查;
其实,HDFS中的这四种角色实际就是几个java进程,也就是相当于几个应用程序,通常Namenode、DataNode、secondaryNode是运行在linux系统中的进程,最后文件的存储还是需要物理磁盘完成,HDFS相当于对文件的管理,负责对文件备份、切分等内容。
关于大数据学习,Hadoop HDFS核心角色及作用,以上就为大家做了大致的介绍了。HDFS作为分布式文件系统来说,其在大数据技术生态当中的地位不必特意强调,学习阶段要掌握扎实。成都加米谷大数据,专业大数据培训,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!




