大数据学习:Flink API编程初级入门
作者:张老师 浏览次数: 2021-05-18 17:13
作为大数据生态圈越来越活跃的框架,Flink的热度持续走高,自然也成为大数据学习阶段必须攻克的一大重难点。Flink编程,一个重要的思想就是API编程,今天的大数据学习分享,我们就来讲讲Flink API编程初级入门。
一、Flink API介绍
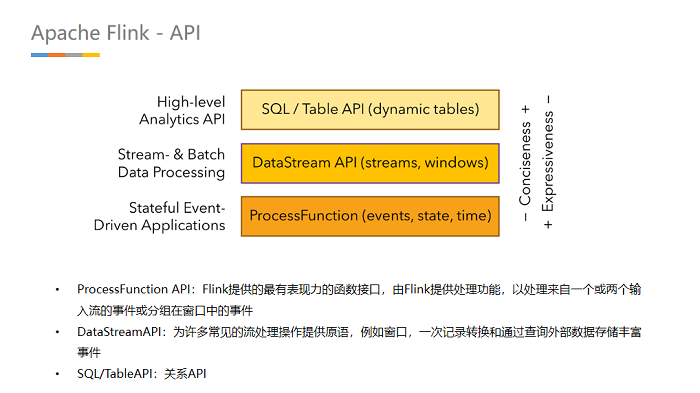
API通常分为三层,由上而下可分为SQL/Table API、DataStream API、ProcessFunction三层,API的表达能力及业务抽象能力都非常强大,但越接近SQL层,表达能力会逐步减弱,抽象能力会增强,反之,ProcessFunction层API的表达能力非常强,可以进行多种灵活方便的操作,但抽象能力也相对越小。
实际上,大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs)进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。DataSet API为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
在实际编程任务当中,核心API分为流处理DataStream和批处理DataSetAPI,一般用于java、scala开发,使用较多。其次是TableAPI,以表为中心的声明式编程API。最顶层的是SQL,也是现在非常活跃开发的Flink SQL,但是实时sql和离线sql在使用上还是需要注意区别。
二、Table API/SQL是如何转换为程序运行的?
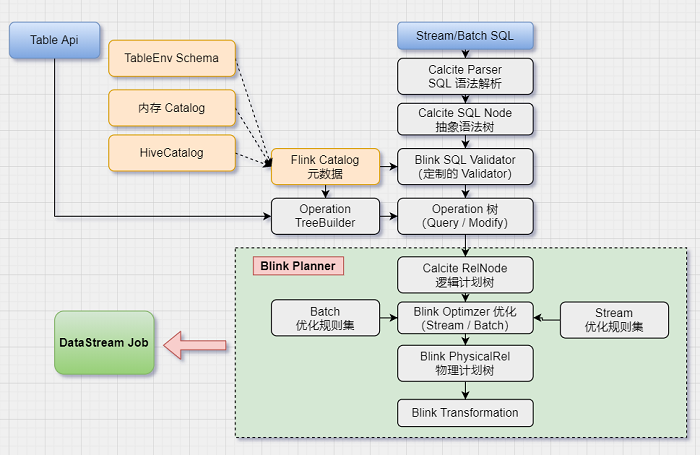
SQL执行被分成两个大的阶段,从SQL语句到Operation,从Operation到Transformation,然后就进入分布式执行的阶段。
1、前置知识:Apache Calcite
Apache Calcite是个动态数据管理框架,具备很多数据库管理系统的功能,如SQL解析,SQL校验,SQL查询优化,SQL生成以及数据连接查询等,但是并不存储元数据和基本数据,不包含处理数据的算法。
由于舍弃了这些功能,Calcite可以在应用和数据存储,数据处理引擎之间很好的扮演中介的角色。
它不受上层编程语言的限制,前端可以使用SQL、Pig、Cascading等语言,只要通过Calcite提供的SQL Api将它们转化成关系代数的抽象语法树即可,并根据一定的规则和成本对抽象语法树进行优化,最后推给各个数据处理引擎来执行。
所以Calcite不涉及物理规划层,它通过扩展适配器来连接多种后端的数据源和数据处理引擎,如Hive,Drill,Flink,Phoenix。
2、SQL语句到Operation过程
首先使用Calcite对SQL语句进行解析,获取SQL Node,再根据不同的SQL类型分别进行转换,校验语法的合法性,再根据语句类型(DQL、DML、DDL)转换成对应的算子树。
对于SQL查询语句而言,会转换为QueryOperation树。
3、Operation到Transformation过程
首先Operation先转换为Calcite的逻辑计划树,再对应地转换为Flink的逻辑计划树,然后进行优化。
优化后的逻辑树转换为Flink的物理计划,然后物理计划通过代码生成算子、UDF、表达式等代码,包装到Transformation中,形成Transformation流水线,再转换为StreamGraph,最终就可以提交到Flink集群真正运行起来了。
4、元数据
元数据是是Flink SQL处理数据非常重要的一个部分,元数据描述了Flink处理的读取和写出的数据的结构以及数据的访问方法等信息,没有元数据,Flink就无法对SQL进行校验和优化了。
元数据包含以下信息:
库
表
视图
UDF
表字段
在Flink中,Catalog是元数据的核心抽象,目前Flink实现了内存小GenericMemoryCatalog和HiveCatalog两种Catalog。
5、优化器
SQL优化器很大程度上决定了一个系统的执行性能。查询优化器分成两类,基于规则的优化器(Rule-Based Optimizer,RBO)和基于代价的优化器(Cost-Based Optimizer,CBO)。
RBO规则优化,主要就是等价改变查询语句的形式,以便产生更好的逻辑执行计划,比如重写用户的查询(谓词推进,物化视图重写,视图合并等),然后还需要将逻辑执行计划变成物理执行计划。
CBO代价优化,除了做上述RBO的规则优化外,还会通过复杂的算法统计信息,统计各个执行计划的执行成本,从不同的执行计划中选择出执行代价最小的一个计划,转换为Flink的执行计划。
三、总结
Flink Table API/SQL提供了对用户友好的接口来更高效的完成实时流式程序的开发。
Flink依托Apache Calcite提供的SQL解析、优化框架,解析构建为逻辑计划树,通过Planner层层优化为Flink可以运行的内部结构,最终提交到Flink集群上运行。
关于大数据学习,Flink API编程初级入门,以上就为大家做了基本的介绍了。在Flink的实际开发任务当中,不同层级的API满足不同人员的需求,性能高效得到肯定。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服获取!
一、Flink API介绍
API通常分为三层,由上而下可分为SQL/Table API、DataStream API、ProcessFunction三层,API的表达能力及业务抽象能力都非常强大,但越接近SQL层,表达能力会逐步减弱,抽象能力会增强,反之,ProcessFunction层API的表达能力非常强,可以进行多种灵活方便的操作,但抽象能力也相对越小。
实际上,大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs)进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。DataSet API为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
在实际编程任务当中,核心API分为流处理DataStream和批处理DataSetAPI,一般用于java、scala开发,使用较多。其次是TableAPI,以表为中心的声明式编程API。最顶层的是SQL,也是现在非常活跃开发的Flink SQL,但是实时sql和离线sql在使用上还是需要注意区别。
二、Table API/SQL是如何转换为程序运行的?
SQL执行被分成两个大的阶段,从SQL语句到Operation,从Operation到Transformation,然后就进入分布式执行的阶段。
1、前置知识:Apache Calcite
Apache Calcite是个动态数据管理框架,具备很多数据库管理系统的功能,如SQL解析,SQL校验,SQL查询优化,SQL生成以及数据连接查询等,但是并不存储元数据和基本数据,不包含处理数据的算法。
由于舍弃了这些功能,Calcite可以在应用和数据存储,数据处理引擎之间很好的扮演中介的角色。
它不受上层编程语言的限制,前端可以使用SQL、Pig、Cascading等语言,只要通过Calcite提供的SQL Api将它们转化成关系代数的抽象语法树即可,并根据一定的规则和成本对抽象语法树进行优化,最后推给各个数据处理引擎来执行。
所以Calcite不涉及物理规划层,它通过扩展适配器来连接多种后端的数据源和数据处理引擎,如Hive,Drill,Flink,Phoenix。
2、SQL语句到Operation过程
首先使用Calcite对SQL语句进行解析,获取SQL Node,再根据不同的SQL类型分别进行转换,校验语法的合法性,再根据语句类型(DQL、DML、DDL)转换成对应的算子树。
对于SQL查询语句而言,会转换为QueryOperation树。
3、Operation到Transformation过程
首先Operation先转换为Calcite的逻辑计划树,再对应地转换为Flink的逻辑计划树,然后进行优化。
优化后的逻辑树转换为Flink的物理计划,然后物理计划通过代码生成算子、UDF、表达式等代码,包装到Transformation中,形成Transformation流水线,再转换为StreamGraph,最终就可以提交到Flink集群真正运行起来了。
4、元数据
元数据是是Flink SQL处理数据非常重要的一个部分,元数据描述了Flink处理的读取和写出的数据的结构以及数据的访问方法等信息,没有元数据,Flink就无法对SQL进行校验和优化了。
元数据包含以下信息:
库
表
视图
UDF
表字段
在Flink中,Catalog是元数据的核心抽象,目前Flink实现了内存小GenericMemoryCatalog和HiveCatalog两种Catalog。
5、优化器
SQL优化器很大程度上决定了一个系统的执行性能。查询优化器分成两类,基于规则的优化器(Rule-Based Optimizer,RBO)和基于代价的优化器(Cost-Based Optimizer,CBO)。
RBO规则优化,主要就是等价改变查询语句的形式,以便产生更好的逻辑执行计划,比如重写用户的查询(谓词推进,物化视图重写,视图合并等),然后还需要将逻辑执行计划变成物理执行计划。
CBO代价优化,除了做上述RBO的规则优化外,还会通过复杂的算法统计信息,统计各个执行计划的执行成本,从不同的执行计划中选择出执行代价最小的一个计划,转换为Flink的执行计划。
三、总结
Flink Table API/SQL提供了对用户友好的接口来更高效的完成实时流式程序的开发。
Flink依托Apache Calcite提供的SQL解析、优化框架,解析构建为逻辑计划树,通过Planner层层优化为Flink可以运行的内部结构,最终提交到Flink集群上运行。
关于大数据学习,Flink API编程初级入门,以上就为大家做了基本的介绍了。在Flink的实际开发任务当中,不同层级的API满足不同人员的需求,性能高效得到肯定。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服获取!




