大数据培训:Kafka消息存储到Broker的流程
作者:张老师 浏览次数: 2021-05-11 17:05
Kafka作为分布式消息系统,在大数据平台架构层面,承担着消息流转和存储支持的重要任务。消息经kafka引入到大数据系统平台,存储是一道重要的关卡。今天的大数据培训分享,我们就主要来讲讲Kafka消息存储到Broker的流程。

一、Kafka客户端组件
KafkaProducer:
KafkaProducer 是一个生产者客户端的进程,通过该对象启动生产者来发送消息。
RecordAccumulator:
RecordAccumulator 是一个记录收集器,用于收集客户端发送的消息,并将收集到的消息暂存到客户端缓存中。
Sender:
Sender 是一个发送线程,负责读取记录收集器中缓存的批量消息,经过一些中间转换操作,将要发送的数据准备好,然后交由 Selector 进行网络传输。
Selector:
Selector 是一个选择器,用于处理网络连接和读写处理,使用网络连接处理客户端上的网络请求。
通过使用以上四大组件即可完成客户端消息的发送工作。消息在网络中传输的方式只能通过二级制的方式,所以首先需要将消息序列化为二进制形式缓存在客户端,kafka 使用了双端队列的方式将消息缓存起来,然后使用发送线程(Sender)读取队列中的消息交给 Selector 进行网络传输发送给服务端(Broker)。
二、客户端缓存存储模型
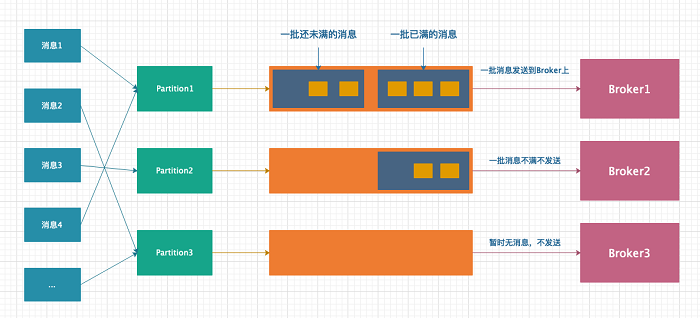
从上图可以看出,一条消息首先需要确定要被存储到那个partition 对应的双端队列上;其次,存储消息的双端队列是以批的维度存储的,即 N 条消息组成一批,一批消息最多存储 N 条,超过后则新建一个组来存储新消息;其次,新来的消息总是从左侧写入,即越靠左侧的消息产生的时间越晚;最后,只有当一批消息凑够 N 条后才会发送给 Broker,否则不会发送到 Broker 上。
了解了客户端存储模型后,来探讨下确定消息的 partition(分区)位置?
三、确定消息的 partition 位置
消息可分为两种,一种是指定了 key 的消息,一种是没有指定 key 的消息。
对于指定了 key 的消息,partition 位置的计算方式为:Utils.murmur2(key) % numPartitions,即先对 key 进行哈希计算,然后在于 partition 个数求余,从而得到该条消息应该被存储在哪个 partition 上。
对于没有指定 key 的消息,partition 位置的计算方式为:采用 round-robin 方式确定 partition 位置,即采用轮询的方式,平均的将消息分布到不同的 partition 上,从而避免某些 partition 数据量过大影响 Broker 和消费端性能。
注意:
由于 partition 有主副的区分,此处参与计算的 partition 数量是当前有主 partition 的数量,即如果某个 partition 无主的时候,则此 partition 是不能够进行数据写入的。
稍微解释一下,主副 partition 的机制是为了提高 kafka 系统的容错性的,即当某个 Broker 意外宕机时,在此 Broker 上的主 partition 状态为不可读写时(只有主 partition 可对外提供读写服务,副 partition 只有数据备份的功能),kafka 会从主 partition 对应的 N 个副 partition 中挑选一个,并将其状态改为主 partition,从而继续对外提供读写操作。
消息被确定分配到某个 partition 对应记录收集器(即双端队列)后,接下来,发送线程(Sender)从记录收集器中收集满足条件的批数据发送给 Broker,那么发送线程是如何收集满足条件的批数据的?批数据是按照 partition 维度发送的还是按照 Broker 维度发送数据的?
四、发送线程的工作原理
Sender 线程的主要工作是收集满足条件的批数据,何为满足条件的批数据?缓存数据是以批维度存储的,当一批数据量达到指定的 N 条时,就满足发送给 Broker 的条件了。
partition 维度和 Broker 维度发送消息模型对比。
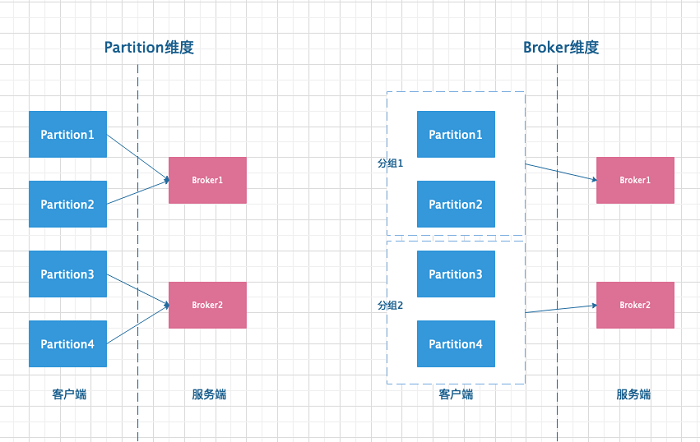
从图中可以看出,左侧按照 partition 维度发送消息,每个 partition 都需要和 Broker 建连,总共发生了四次网络连接。而右侧将分布在同一个 Broker 的 partition 按组聚合后在与 Broker 建连,只需要两次网络连接即可。所以 Kafka 选择右侧的方式。
Sender 的主要工作
第一步:扫描记录收集器中满足条件的批数据,然后将 partition -> 批数据映射转换成 BrokerId -> N 批数据的映射。
第二步:Sender 线程会为每个 BrokerId 创建一个客户端请求,然后将请求交给 NetWorkClient,由 NetWrokClient 去真正发送网络请求到 Broker。
NetWorkClient 的工作内容
Sender 线程准备好要发送的数据后,交由 NetWorkClient 来进行网络相关操作。主要包括客户端与服务端的建连、发送客户端请求、接受服务端响应。完成如上一系列的工作主要由如下方法完成。
reday()方法。从记录收集器获取准备完毕的节点,并连接所有准备好的节点。
send()方法。为每个节点创建一个客户端请求,然后将请求暂时存到节点对应的 Channel(通道)中。
poll()方法。该方法会真正轮询网络请求,发送请求给服务端节点和接受服务端的响应。
关于大数据培训,Kafka消息存储到Broker的流程,以上就为大家做了大致的讲解了。在大数据学习当中,Kafka是一个重要的生态圈组件,这个部分必须要多去深入理解。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!
一、Kafka客户端组件
KafkaProducer:
KafkaProducer 是一个生产者客户端的进程,通过该对象启动生产者来发送消息。
RecordAccumulator:
RecordAccumulator 是一个记录收集器,用于收集客户端发送的消息,并将收集到的消息暂存到客户端缓存中。
Sender:
Sender 是一个发送线程,负责读取记录收集器中缓存的批量消息,经过一些中间转换操作,将要发送的数据准备好,然后交由 Selector 进行网络传输。
Selector:
Selector 是一个选择器,用于处理网络连接和读写处理,使用网络连接处理客户端上的网络请求。
通过使用以上四大组件即可完成客户端消息的发送工作。消息在网络中传输的方式只能通过二级制的方式,所以首先需要将消息序列化为二进制形式缓存在客户端,kafka 使用了双端队列的方式将消息缓存起来,然后使用发送线程(Sender)读取队列中的消息交给 Selector 进行网络传输发送给服务端(Broker)。
二、客户端缓存存储模型
从上图可以看出,一条消息首先需要确定要被存储到那个partition 对应的双端队列上;其次,存储消息的双端队列是以批的维度存储的,即 N 条消息组成一批,一批消息最多存储 N 条,超过后则新建一个组来存储新消息;其次,新来的消息总是从左侧写入,即越靠左侧的消息产生的时间越晚;最后,只有当一批消息凑够 N 条后才会发送给 Broker,否则不会发送到 Broker 上。
了解了客户端存储模型后,来探讨下确定消息的 partition(分区)位置?
三、确定消息的 partition 位置
消息可分为两种,一种是指定了 key 的消息,一种是没有指定 key 的消息。
对于指定了 key 的消息,partition 位置的计算方式为:Utils.murmur2(key) % numPartitions,即先对 key 进行哈希计算,然后在于 partition 个数求余,从而得到该条消息应该被存储在哪个 partition 上。
对于没有指定 key 的消息,partition 位置的计算方式为:采用 round-robin 方式确定 partition 位置,即采用轮询的方式,平均的将消息分布到不同的 partition 上,从而避免某些 partition 数据量过大影响 Broker 和消费端性能。
注意:
由于 partition 有主副的区分,此处参与计算的 partition 数量是当前有主 partition 的数量,即如果某个 partition 无主的时候,则此 partition 是不能够进行数据写入的。
稍微解释一下,主副 partition 的机制是为了提高 kafka 系统的容错性的,即当某个 Broker 意外宕机时,在此 Broker 上的主 partition 状态为不可读写时(只有主 partition 可对外提供读写服务,副 partition 只有数据备份的功能),kafka 会从主 partition 对应的 N 个副 partition 中挑选一个,并将其状态改为主 partition,从而继续对外提供读写操作。
消息被确定分配到某个 partition 对应记录收集器(即双端队列)后,接下来,发送线程(Sender)从记录收集器中收集满足条件的批数据发送给 Broker,那么发送线程是如何收集满足条件的批数据的?批数据是按照 partition 维度发送的还是按照 Broker 维度发送数据的?
四、发送线程的工作原理
Sender 线程的主要工作是收集满足条件的批数据,何为满足条件的批数据?缓存数据是以批维度存储的,当一批数据量达到指定的 N 条时,就满足发送给 Broker 的条件了。
partition 维度和 Broker 维度发送消息模型对比。
从图中可以看出,左侧按照 partition 维度发送消息,每个 partition 都需要和 Broker 建连,总共发生了四次网络连接。而右侧将分布在同一个 Broker 的 partition 按组聚合后在与 Broker 建连,只需要两次网络连接即可。所以 Kafka 选择右侧的方式。
Sender 的主要工作
第一步:扫描记录收集器中满足条件的批数据,然后将 partition -> 批数据映射转换成 BrokerId -> N 批数据的映射。
第二步:Sender 线程会为每个 BrokerId 创建一个客户端请求,然后将请求交给 NetWorkClient,由 NetWrokClient 去真正发送网络请求到 Broker。
NetWorkClient 的工作内容
Sender 线程准备好要发送的数据后,交由 NetWorkClient 来进行网络相关操作。主要包括客户端与服务端的建连、发送客户端请求、接受服务端响应。完成如上一系列的工作主要由如下方法完成。
reday()方法。从记录收集器获取准备完毕的节点,并连接所有准备好的节点。
send()方法。为每个节点创建一个客户端请求,然后将请求暂时存到节点对应的 Channel(通道)中。
poll()方法。该方法会真正轮询网络请求,发送请求给服务端节点和接受服务端的响应。
关于大数据培训,Kafka消息存储到Broker的流程,以上就为大家做了大致的讲解了。在大数据学习当中,Kafka是一个重要的生态圈组件,这个部分必须要多去深入理解。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!




