大数据培训:HDFS的HA详解
作者:张老师 浏览次数: 2021-04-12 17:35
HDFS的高可用HA,简单来说,其实就是保障服务的不中断,能够在大规模的数据场景下,确保系统稳定运行,减少突发故障可能带来的数据损失。今天的大数据培训分享,我们就具体来讲讲HDFS的HA高可用,到底是是什么,如何实现……

HDFS 的HA原理
所谓HA,即高可用(7*24小时不中断服务),实现高可用最关键的是消除单点故障。
HDFS的HA就是通过双namenode来防止单点问题,一旦主NameNode出现故障,可以迅速切换至备用的NameNode。两个namenode有不同的状态,状态分别是Active和Standby。(备用)Namenode作为热备份,在机器发生故障时能够快速进行故障转移,同时在日常维护的时候进行Namenode切换。
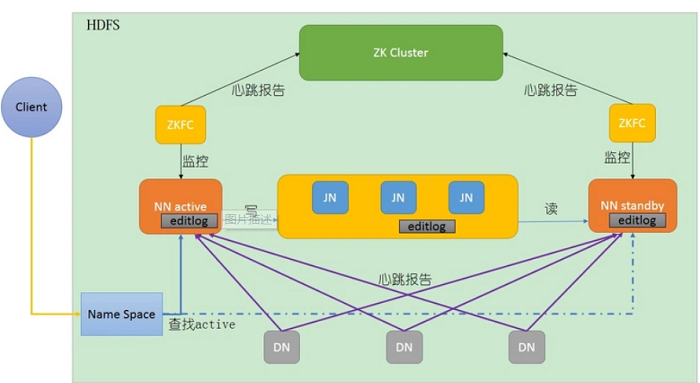
HDFS HA的几大重点
1)保证两个namenode里面的内存中存储的文件的元数据同步
->namenode启动时,会读镜像文件
2)变化的记录信息同步
3)日志文件的安全性
->分布式的存储日志文件(cloudera公司提出来的)
->2n+1个,使用副本数保证安全性
->使用zookeeper监控
->监控两个namenode,当一个出现了问题,可以达到自动故障转移。
->如果出现了问题,不会影响整个集群
->zookeeper对时间同步要求比较高。
4)客户端如何知道访问哪一个namenode
->使用proxy代理
->隔离机制
->使用的是sshfence
->两个namenode之间无密码登录
5)namenode是哪一个是active
->zookeeper通过选举选出zookeeper。
->然后zookeeper开始监控,如果出现文件,自动故障转移。
HDFS HA的实现流程
主Namenode处理所有的操作请求,而Standby只是作为slave,主要进行同步主Namenode的状态,保证发生故障时能够快速切换,并且数据一致。为了两个Namenode数据保持同步,两个Namenode都与一组Journal Node进行通信。当主Namenode进行任务的namespace操作时,都会同步修改日志到Journal Node节点中。
Standby Namenode持续监控这些edit,当监测到变化时,将这些修改同步到自己的namespace。当进行故障转移时,Standby在成为Active Namenode之前,会确保自己已经读取了Journal Node中的所有edit日志,从而保持数据状态与故障发生前一致。
为了确保故障转移能够快速完成,Standby Namenode需要维护最新的Block位置信息,即每个Block副本存放在集群中的哪些节点上。为了达到这一点,Datanode同时配置主备两个Namenode,并同时发送Block报告和心跳到两台Namenode。
任何时刻集群中只有一个Namenode处于Active状态,否则可能出现数据丢失或者数据损坏。当两台Namenode都认为自己的Active Namenode时,会同时尝试写入数据。为了防止这种脑裂现象,Journal Nodes只允许一个Namenode写入数据,内部通过维护epoch数来控制,从而安全地进行故障转移。
关于大数据培训,HDFS的HA高可用机制,以上就为大家做了基本的介绍了。HDFS作为分布式文件系统,对于后续的各个数据处理环节提供底层支持,其稳定运行对于后续的环节非常关键。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及学习资料,可联系客服获取!
HDFS 的HA原理
所谓HA,即高可用(7*24小时不中断服务),实现高可用最关键的是消除单点故障。
HDFS的HA就是通过双namenode来防止单点问题,一旦主NameNode出现故障,可以迅速切换至备用的NameNode。两个namenode有不同的状态,状态分别是Active和Standby。(备用)Namenode作为热备份,在机器发生故障时能够快速进行故障转移,同时在日常维护的时候进行Namenode切换。
HDFS HA的几大重点
1)保证两个namenode里面的内存中存储的文件的元数据同步
->namenode启动时,会读镜像文件
2)变化的记录信息同步
3)日志文件的安全性
->分布式的存储日志文件(cloudera公司提出来的)
->2n+1个,使用副本数保证安全性
->使用zookeeper监控
->监控两个namenode,当一个出现了问题,可以达到自动故障转移。
->如果出现了问题,不会影响整个集群
->zookeeper对时间同步要求比较高。
4)客户端如何知道访问哪一个namenode
->使用proxy代理
->隔离机制
->使用的是sshfence
->两个namenode之间无密码登录
5)namenode是哪一个是active
->zookeeper通过选举选出zookeeper。
->然后zookeeper开始监控,如果出现文件,自动故障转移。
HDFS HA的实现流程
主Namenode处理所有的操作请求,而Standby只是作为slave,主要进行同步主Namenode的状态,保证发生故障时能够快速切换,并且数据一致。为了两个Namenode数据保持同步,两个Namenode都与一组Journal Node进行通信。当主Namenode进行任务的namespace操作时,都会同步修改日志到Journal Node节点中。
Standby Namenode持续监控这些edit,当监测到变化时,将这些修改同步到自己的namespace。当进行故障转移时,Standby在成为Active Namenode之前,会确保自己已经读取了Journal Node中的所有edit日志,从而保持数据状态与故障发生前一致。
为了确保故障转移能够快速完成,Standby Namenode需要维护最新的Block位置信息,即每个Block副本存放在集群中的哪些节点上。为了达到这一点,Datanode同时配置主备两个Namenode,并同时发送Block报告和心跳到两台Namenode。
任何时刻集群中只有一个Namenode处于Active状态,否则可能出现数据丢失或者数据损坏。当两台Namenode都认为自己的Active Namenode时,会同时尝试写入数据。为了防止这种脑裂现象,Journal Nodes只允许一个Namenode写入数据,内部通过维护epoch数来控制,从而安全地进行故障转移。
关于大数据培训,HDFS的HA高可用机制,以上就为大家做了基本的介绍了。HDFS作为分布式文件系统,对于后续的各个数据处理环节提供底层支持,其稳定运行对于后续的环节非常关键。成都加米谷大数据,专业大数据培训机构,大数据开发,数据分析与挖掘,零基础班本月正在招生中,课程大纲及学习资料,可联系客服获取!
- 上一篇:大数据学习:Hadoop的RPC原理解析
- 下一篇:学好大数据开发的基础是什么?




