大数据学习:Spark SQL入门实操示例
作者:张老师 浏览次数: 2021-03-26 17:53
目前主流的大数据计算框架,Spark依然占据重要的份额,不管是作为大数据开发还是大数据分析人员,都需要对Spark框架做到相应程度的掌握。今天的大数据学习分享,我们就来讲讲Spark SQL的部分,实操应该怎么去上手。
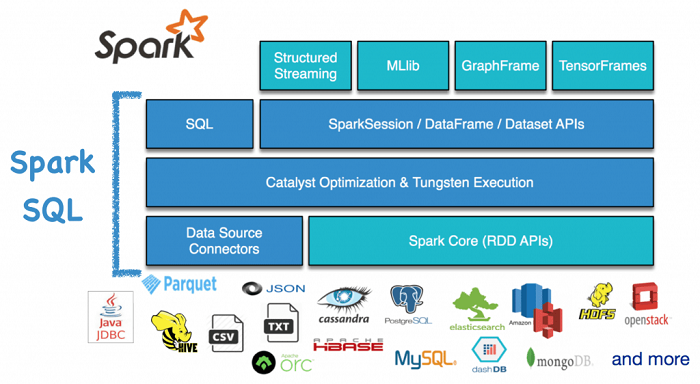
1.构建入口
Spark SQL中所有功能的入口点是SparkSession类-Spark 2.0引入的新概念,它为用户提供统一的切入点。
早期Spark的切入点是SparkContext,通过它来创建和操作数据集,对于不同的API需要不同的context。
比如:使用sql-需要sqlContext,使用hive-需要hiveContext,使用streaming-需要StreamingContext。SparkSession封装了SparkContext和SQLContext。
要创建一个 SparkSession使用SparkSession.builder():
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
2.创建DataFrame
在一个SparkSession中,应用程序可以从结构化的数据文件、Hive的table、外部数据库和RDD中创建一个DataFrame。
举个例子, 下面就是基于一个JSON文件创建一个DataFrame:
val df =spark.read.json("examples/src/main/resources/people.json")
// 显示出DataFrame的内容
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
3.执行SQL查询
// 将DataFrame注册成一个临时视图
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19|Justin|
// +----+-------+
SparkSession的SQL函数可以让应用程序以编程的方式运行SQL查询,并将结果作为一个 DataFrame返回。
例子中createOrReplaceTempView创建的临时视图是session级别的,也就是会随着session的消失而消失。如果你想让一个临时视图在所有session中相互传递并且可用,直到Spark 应用退出,你可以建立一个全局的临时视图,全局的临时视图存在于系统数据库global_temp中,我们必须加上库名去引用它。
// 将一个DataFrame注册成一个全局临时视图
df.createGlobalTempView("people")
// 注意这里的global_temp
spark.sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19|Justin|
// +----+-------+
// 新的session同样可以访问
spark.newSession().sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19|Justin|
// +----+-------+
4.DataFrame操作示例
import spark.implicits._ //导入隐式转换的包
//打印schema
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
//选择一列进行打印
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
//年龄加1
df.select($"name", $"age" +1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
//选取年龄大于21的
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
//聚合操作
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
5.创建DataSet
Dataset和RDD比较类似,与RDD不同的是实现序列化和反序列化的方式,RDD是使用Java serialization或者Kryo,而Dataset是使用Encoder。
Encoder的动态特性使得Spark可以在执行filtering、sorting和hashing等许多操作时无需把字节反序列化为对象。
// 一个简单的Seq转成DataSet,会有默认的schema
val primitiveDS = Seq(1, 2, 3).toDS().show
// +-----+
// |value|
// +-----+
// | 1|
// | 2|
// | 3|
// +-----+
case class Person(name: String, age: Long)
// 通过反射转换为DataSet
val caseClassDS = Seq(Person("Andy",32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// DataFrame指定一个类则为DataSet
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
通过上述的代码可以看出创建DataSet的代码很简单,一个toDs就可以自动推断出schema的类型,读取json这种结构化的数据得到的是一个DataFrame,再指定它的类则为DataSet。
6.RDD的互操作性
RDD的互操作性指的是RDD和DataFrame的相互转换,DataFrame转RDD很简单,复杂的是RDD转DataFrame。
目前Spark SQL有两种方法:
反射推断
Spark SQL 的 Scala 接口支持自动转换一个包含 Case Class的 RDD 为DataFrame。Case Class 定义了表的Schema。Case class 的参数名使用反射读取并且成为了列名。Case class 也可以是嵌套的或者包含像 Seq 或者 Array 这样的复杂类型,这个 RDD 能够被隐式转换成一个 DataFrame 然后被注册为一个表。
// 开启隐式转换
import spark.implicits._
// 读入文本文件并最终转化成DataFrame
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
// 将DataFrame注册成表
peopleDF.createOrReplaceTempView("people")
// 执行一条sql查询
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
// 通过map操作后得到的是RDD
teenagersDF.map(teenager => "Name: " +teenager(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
另一种更加简单的操作是将RDD中每一行类型变为tuple类型,然后使用toDF依次赋予字段名,需要注意的是使用tuple最高可以支持22个字段。
// 开启隐式转换
import spark.implicits._
// 读入文本文件并最终转化成DataFrame
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => (attributes(0), attributes(1).trim.toInt))
.toDF("name","age")
//peopleDF: org.apache.spark.sql.DataFrame = [name:string, age: int]
构造Schema
在无法提前定义schema的情况下,RDD转DataFrame或者DataSet需要构造Schema。
构建一个Schema并将它应用到一个已存在的RDD编程接口需要以下四个步骤:
a.从原始的RDD创建一个tuple或者列表类型的RDD
b.创建一个StructType来匹配RDD中的结构
c.将生成的RDD转换成Row类型的RDD
d.通过createDataFrame方法将Schema应用到RDD
//需要导入类型相关的包
import org.apache.spark.sql.types._
//读取hdfs上的文本文件,保存到rdd中
val peopleRDD =spark.sparkContext.textFile("examples/src/main/resources/people.txt")
// 这里的schema是一个字符串,可以来自于其他未知内容的文件,需要注意的是-这里明确写出来只是为了演示,并不代表提前知道schema信息。
val schemaString = "name age"
// 将有schema信息的字符串转变为StructField类型
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable =true))
//通过StructType方法读入schema
val schema = StructType(fields)
// 将RDD转换成Row类型的RDD
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// 应用schema信息到Row类型的RDD
val peopleDF = spark.createDataFrame(rowRDD,schema)
关于大数据学习,Spark SQL入门实操示例,以上就为大家做了基本的介绍了。Spark SQL在实际操作当中,其实并不难,主要是需要对常用的语言要记忆准确,逻辑要理解清楚。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及学习视频可联系客服获取!
1.构建入口
Spark SQL中所有功能的入口点是SparkSession类-Spark 2.0引入的新概念,它为用户提供统一的切入点。
早期Spark的切入点是SparkContext,通过它来创建和操作数据集,对于不同的API需要不同的context。
比如:使用sql-需要sqlContext,使用hive-需要hiveContext,使用streaming-需要StreamingContext。SparkSession封装了SparkContext和SQLContext。
要创建一个 SparkSession使用SparkSession.builder():
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
2.创建DataFrame
在一个SparkSession中,应用程序可以从结构化的数据文件、Hive的table、外部数据库和RDD中创建一个DataFrame。
举个例子, 下面就是基于一个JSON文件创建一个DataFrame:
val df =spark.read.json("examples/src/main/resources/people.json")
// 显示出DataFrame的内容
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
3.执行SQL查询
// 将DataFrame注册成一个临时视图
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19|Justin|
// +----+-------+
SparkSession的SQL函数可以让应用程序以编程的方式运行SQL查询,并将结果作为一个 DataFrame返回。
例子中createOrReplaceTempView创建的临时视图是session级别的,也就是会随着session的消失而消失。如果你想让一个临时视图在所有session中相互传递并且可用,直到Spark 应用退出,你可以建立一个全局的临时视图,全局的临时视图存在于系统数据库global_temp中,我们必须加上库名去引用它。
// 将一个DataFrame注册成一个全局临时视图
df.createGlobalTempView("people")
// 注意这里的global_temp
spark.sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19|Justin|
// +----+-------+
// 新的session同样可以访问
spark.newSession().sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19|Justin|
// +----+-------+
4.DataFrame操作示例
import spark.implicits._ //导入隐式转换的包
//打印schema
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
//选择一列进行打印
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
//年龄加1
df.select($"name", $"age" +1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
//选取年龄大于21的
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
//聚合操作
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
5.创建DataSet
Dataset和RDD比较类似,与RDD不同的是实现序列化和反序列化的方式,RDD是使用Java serialization或者Kryo,而Dataset是使用Encoder。
Encoder的动态特性使得Spark可以在执行filtering、sorting和hashing等许多操作时无需把字节反序列化为对象。
// 一个简单的Seq转成DataSet,会有默认的schema
val primitiveDS = Seq(1, 2, 3).toDS().show
// +-----+
// |value|
// +-----+
// | 1|
// | 2|
// | 3|
// +-----+
case class Person(name: String, age: Long)
// 通过反射转换为DataSet
val caseClassDS = Seq(Person("Andy",32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// DataFrame指定一个类则为DataSet
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
通过上述的代码可以看出创建DataSet的代码很简单,一个toDs就可以自动推断出schema的类型,读取json这种结构化的数据得到的是一个DataFrame,再指定它的类则为DataSet。
6.RDD的互操作性
RDD的互操作性指的是RDD和DataFrame的相互转换,DataFrame转RDD很简单,复杂的是RDD转DataFrame。
目前Spark SQL有两种方法:
反射推断
Spark SQL 的 Scala 接口支持自动转换一个包含 Case Class的 RDD 为DataFrame。Case Class 定义了表的Schema。Case class 的参数名使用反射读取并且成为了列名。Case class 也可以是嵌套的或者包含像 Seq 或者 Array 这样的复杂类型,这个 RDD 能够被隐式转换成一个 DataFrame 然后被注册为一个表。
// 开启隐式转换
import spark.implicits._
// 读入文本文件并最终转化成DataFrame
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
// 将DataFrame注册成表
peopleDF.createOrReplaceTempView("people")
// 执行一条sql查询
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
// 通过map操作后得到的是RDD
teenagersDF.map(teenager => "Name: " +teenager(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
另一种更加简单的操作是将RDD中每一行类型变为tuple类型,然后使用toDF依次赋予字段名,需要注意的是使用tuple最高可以支持22个字段。
// 开启隐式转换
import spark.implicits._
// 读入文本文件并最终转化成DataFrame
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => (attributes(0), attributes(1).trim.toInt))
.toDF("name","age")
//peopleDF: org.apache.spark.sql.DataFrame = [name:string, age: int]
构造Schema
在无法提前定义schema的情况下,RDD转DataFrame或者DataSet需要构造Schema。
构建一个Schema并将它应用到一个已存在的RDD编程接口需要以下四个步骤:
a.从原始的RDD创建一个tuple或者列表类型的RDD
b.创建一个StructType来匹配RDD中的结构
c.将生成的RDD转换成Row类型的RDD
d.通过createDataFrame方法将Schema应用到RDD
//需要导入类型相关的包
import org.apache.spark.sql.types._
//读取hdfs上的文本文件,保存到rdd中
val peopleRDD =spark.sparkContext.textFile("examples/src/main/resources/people.txt")
// 这里的schema是一个字符串,可以来自于其他未知内容的文件,需要注意的是-这里明确写出来只是为了演示,并不代表提前知道schema信息。
val schemaString = "name age"
// 将有schema信息的字符串转变为StructField类型
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable =true))
//通过StructType方法读入schema
val schema = StructType(fields)
// 将RDD转换成Row类型的RDD
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// 应用schema信息到Row类型的RDD
val peopleDF = spark.createDataFrame(rowRDD,schema)
关于大数据学习,Spark SQL入门实操示例,以上就为大家做了基本的介绍了。Spark SQL在实际操作当中,其实并不难,主要是需要对常用的语言要记忆准确,逻辑要理解清楚。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及学习视频可联系客服获取!
- 上一篇:JAVA在大数据行业为何如此重要?
- 下一篇:大数据学习:Spark SQL数据读取




