大数据学习:HDFS数据读取流程详解
作者:张老师 浏览次数: 2021-01-18 16:54
Hadoop是大数据必学的技术框架,而其中的HDFS,是核心三大组件之一,也是基础入门阶段需要搞定的重点和难点。关于HDFS分布式文件系统,之前我们对数据写入阶段已经做了基本的介绍,今天的大数据学习分享,我们接着来讲,HDFS数据读取的详细流程。

HDFS数据读取
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
HDFS读取数据步骤
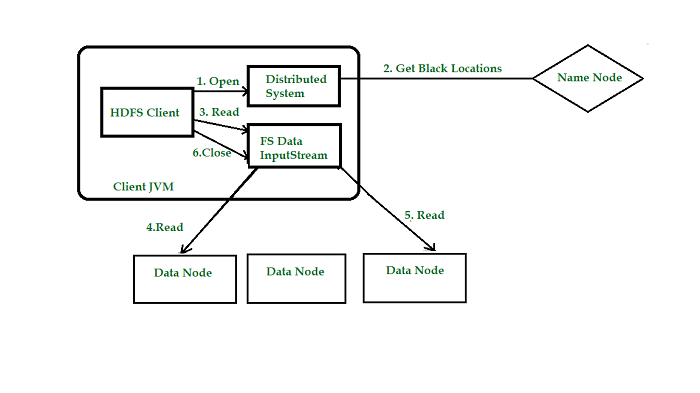
1)客户端向namenode发起RPC调用,请求读取文件数据。
2)namenode检查文件是否存在,如果存在则获取文件的元信息(blockid以及对应的datanode列表)。
3)客户端收到元信息后选取一个网络距离最近的datanode,依次请求读取每个数据块。客户端首先要校检文件是否损坏,如果损坏,客户端会选取另外的datanode请求。
4)datanode与客户端简历socket连接,传输对应的数据块,客户端收到数据缓存到本地,之后写入文件。
5)依次传输剩下的数据块,直到整个文件合并完成。
从某个Datanode获取的数据块有可能是损坏的,损坏可能是由Datanode的存储设备错误、网络错误或者软件bug造成的。HDFS客户端软件实现了对HDFS文件内容的校验和(checksum)检查。当客户端创建一个新的HDFS文件,会计算这个文件每个数据块的校验和,并将校验和作为一个单独的隐藏文件保存在同一个HDFS名字空间下。当客户端获取文件内容后,它会检验从Datanode获取的数据跟相应的校验和文件中的校验和是否匹配,如果不匹配,客户端可以选择从其他Datanode获取该数据块的副本。
HDFS删除数据
HDFS删除数据比较流程相对简单,这里直接列出详细步骤:
1)客户端向namenode发起RPC调用,请求删除文件。namenode检查合法性。
2)namenode查询文件相关元信息,向存储文件数据块的datanode发出删除请求。
3)datanode删除相关数据块。返回结果。
4)namenode返回结果给客户端。
当用户或应用程序删除某个文件时,这个文件并没有立刻从HDFS中删除。实际上,HDFS会将这个文件重命名转移到/trash目录。只要文件还在/trash目录中,该文件就可以被迅速地恢复。文件在/trash中保存的时间是可配置的,当超过这个时间时,Namenode就会将该文件从名字空间中删除。删除文件会使得该文件相关的数据块被释放。
关于大数据学习,HDFS数据读取和数据删除,以上就为大家做了大致的介绍了。HDFS在读取数据和删除数据上,其实与写入数据流程是大致相似的,可以结合起来一起理解和掌握。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!
HDFS数据读取
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
HDFS读取数据步骤
1)客户端向namenode发起RPC调用,请求读取文件数据。
2)namenode检查文件是否存在,如果存在则获取文件的元信息(blockid以及对应的datanode列表)。
3)客户端收到元信息后选取一个网络距离最近的datanode,依次请求读取每个数据块。客户端首先要校检文件是否损坏,如果损坏,客户端会选取另外的datanode请求。
4)datanode与客户端简历socket连接,传输对应的数据块,客户端收到数据缓存到本地,之后写入文件。
5)依次传输剩下的数据块,直到整个文件合并完成。
从某个Datanode获取的数据块有可能是损坏的,损坏可能是由Datanode的存储设备错误、网络错误或者软件bug造成的。HDFS客户端软件实现了对HDFS文件内容的校验和(checksum)检查。当客户端创建一个新的HDFS文件,会计算这个文件每个数据块的校验和,并将校验和作为一个单独的隐藏文件保存在同一个HDFS名字空间下。当客户端获取文件内容后,它会检验从Datanode获取的数据跟相应的校验和文件中的校验和是否匹配,如果不匹配,客户端可以选择从其他Datanode获取该数据块的副本。
HDFS删除数据
HDFS删除数据比较流程相对简单,这里直接列出详细步骤:
1)客户端向namenode发起RPC调用,请求删除文件。namenode检查合法性。
2)namenode查询文件相关元信息,向存储文件数据块的datanode发出删除请求。
3)datanode删除相关数据块。返回结果。
4)namenode返回结果给客户端。
当用户或应用程序删除某个文件时,这个文件并没有立刻从HDFS中删除。实际上,HDFS会将这个文件重命名转移到/trash目录。只要文件还在/trash目录中,该文件就可以被迅速地恢复。文件在/trash中保存的时间是可配置的,当超过这个时间时,Namenode就会将该文件从名字空间中删除。删除文件会使得该文件相关的数据块被释放。
关于大数据学习,HDFS数据读取和数据删除,以上就为大家做了大致的介绍了。HDFS在读取数据和删除数据上,其实与写入数据流程是大致相似的,可以结合起来一起理解和掌握。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析挖掘,零基础班本月正在招生中,课程大纲及试学视频,可联系客服获取!




