大数据培训:HDFS架构演进之路
作者:张老师 浏览次数: 2020-12-29 17:36
Hadoop的核心三大组件之一,HDFS主要负责分布式文件存储,将大规模的数据存储任务拆分成小块,分布到不同的机器上,从而以低成本的方式解决大数据存储问题。今天的大数据培训分享,我们就主要来讲讲伴随着Hadoop的迭代更新,HDFS架构是如何演进的。

众所周知,Hadoop的诞生源于Google三篇论文,也就是我们经常说的“三辆马车”,2006年Hadoop出了第一个发行版本,Hadoop到目前为止发展已经有10余年,版本经过了无数次的更新迭代,业内把Hadoop大的版本分为Hadoop1,hadoop2,Hadoop3三个版本。
而HDFS,也随着Hadoop的更新迭代,在不断完善和优化。
HDFS架构演进
(1)HDFS 1.0架构
一般来说,架构我们分两种,一种就是主从架构,另一种是对等架构。在大数据生态中,常用的对等架构有Zookeeper、Kafka,而HDFS是主从式(master/slave)结构,由NameNode和DataNode以及SecondaryNamenode组成,如下图所示:
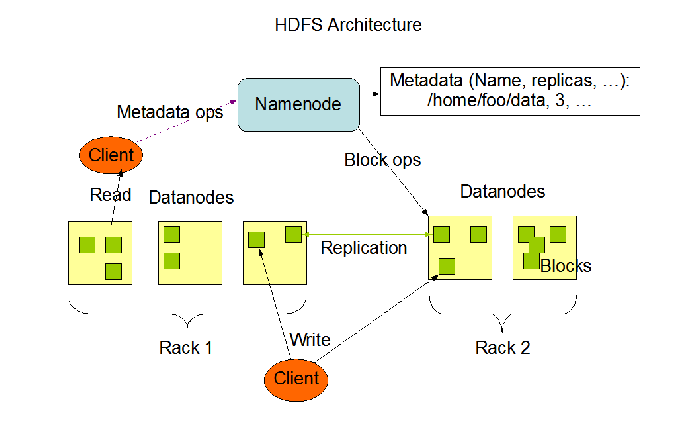
Namenode:属于集群中的中心服务器,管理节点,主要负责管理文件系统的命名空间(namespace)以及客户端对文件的访问,比如打开、关闭、重命名文件或目录,同时管理集群元数据的存储,记录文件中数据块(block)的映射关系。
Datanode:主要负责存储用户数据,处理来自文件系统客户端的请求,保持与namenode的通信,执行namenode的调度指令。
SeconddaryNameNode:主要是合并NameNode的edit logs到fsimage文件。
HDFS 1.0当中,分布式文件系统由一个Namenode和多个Datanode共同组成,这样的组织架构,导致了HDFS 1.0在运行当中出现单点故障以及内存受限的问题。
在实际运行当中,一旦NameNode出现了故障或者宕机,会导致数据丢失。因此在之后的HDFS 2.0架构当中,就对此作了改进。
(2)HDFS 2.0架构
HDFS 2.0采用HA(高可用)的方案,相对于HDFS 1.0来说,Namenode会区分两种状态,active和standby,正常工作的时候时候由active Namenode对外提供服务,standby Namenode则会从journalnode同步元数据,保证和active保持元数据一致。
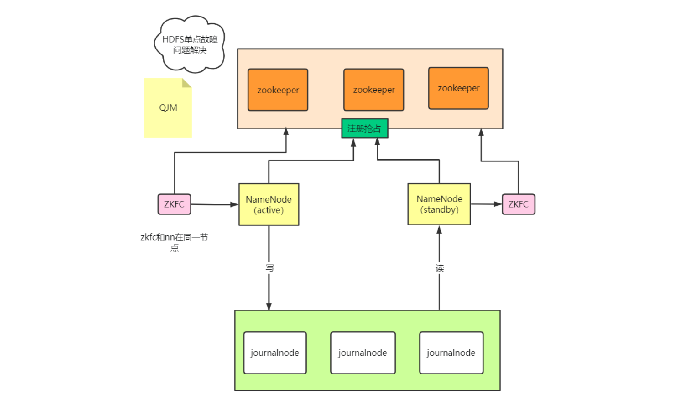
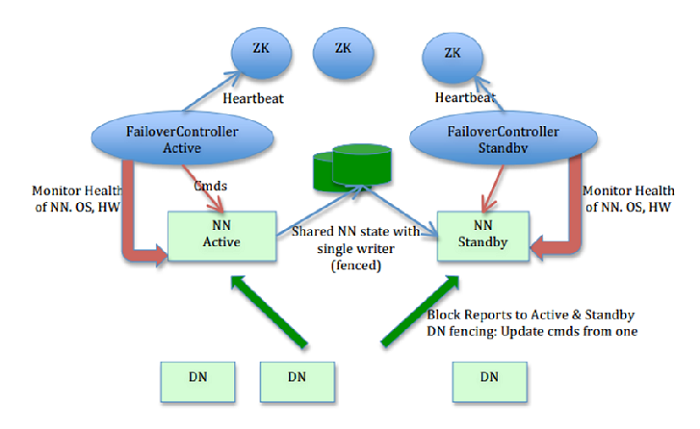
当active Namenode出现故障或者宕机的时候,standby会自动切换为新的active Namenode对外提供服务,并且HA对外提供了统一的访问名称,对于用户来说,不管访问的Namenode是active状态还是standby状态都是无感知的。
此外HDFS 2.0通过federation(联邦)机制解决了内存受限的问题。HDFS 2.0采用了建仓库的办法,也就是federation机制,但是一般适用于1000+规模的集群,小公司基本是用不上。
(3)HDFS 3.0架构
HDFS 3.0在架构上相对于HDFS 2.0没什么大的调整,HDFS 2.0只支持至多两个Namenode,而HDFS 3.0在2.0的基础上增加了多个Namenode的支持,提供集群可用性。
HDFS 3.0主要聚焦提升底层数据存储优化,降低数据开销的成本,采用纠错码技术提高集群的容错性。
关于大数据培训,HDFS架构演进之路,以上就为大家做了简单的介绍了。作为大数据主流基础架构的Hadoop,在实际发展当中历经多次更新和迭代,而其中的HDFS架构,也是在不断完善和优化的。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服领取!
众所周知,Hadoop的诞生源于Google三篇论文,也就是我们经常说的“三辆马车”,2006年Hadoop出了第一个发行版本,Hadoop到目前为止发展已经有10余年,版本经过了无数次的更新迭代,业内把Hadoop大的版本分为Hadoop1,hadoop2,Hadoop3三个版本。
而HDFS,也随着Hadoop的更新迭代,在不断完善和优化。
HDFS架构演进
(1)HDFS 1.0架构
一般来说,架构我们分两种,一种就是主从架构,另一种是对等架构。在大数据生态中,常用的对等架构有Zookeeper、Kafka,而HDFS是主从式(master/slave)结构,由NameNode和DataNode以及SecondaryNamenode组成,如下图所示:
Namenode:属于集群中的中心服务器,管理节点,主要负责管理文件系统的命名空间(namespace)以及客户端对文件的访问,比如打开、关闭、重命名文件或目录,同时管理集群元数据的存储,记录文件中数据块(block)的映射关系。
Datanode:主要负责存储用户数据,处理来自文件系统客户端的请求,保持与namenode的通信,执行namenode的调度指令。
SeconddaryNameNode:主要是合并NameNode的edit logs到fsimage文件。
HDFS 1.0当中,分布式文件系统由一个Namenode和多个Datanode共同组成,这样的组织架构,导致了HDFS 1.0在运行当中出现单点故障以及内存受限的问题。
在实际运行当中,一旦NameNode出现了故障或者宕机,会导致数据丢失。因此在之后的HDFS 2.0架构当中,就对此作了改进。
(2)HDFS 2.0架构
HDFS 2.0采用HA(高可用)的方案,相对于HDFS 1.0来说,Namenode会区分两种状态,active和standby,正常工作的时候时候由active Namenode对外提供服务,standby Namenode则会从journalnode同步元数据,保证和active保持元数据一致。
当active Namenode出现故障或者宕机的时候,standby会自动切换为新的active Namenode对外提供服务,并且HA对外提供了统一的访问名称,对于用户来说,不管访问的Namenode是active状态还是standby状态都是无感知的。
此外HDFS 2.0通过federation(联邦)机制解决了内存受限的问题。HDFS 2.0采用了建仓库的办法,也就是federation机制,但是一般适用于1000+规模的集群,小公司基本是用不上。
(3)HDFS 3.0架构
HDFS 3.0在架构上相对于HDFS 2.0没什么大的调整,HDFS 2.0只支持至多两个Namenode,而HDFS 3.0在2.0的基础上增加了多个Namenode的支持,提供集群可用性。
HDFS 3.0主要聚焦提升底层数据存储优化,降低数据开销的成本,采用纠错码技术提高集群的容错性。
关于大数据培训,HDFS架构演进之路,以上就为大家做了简单的介绍了。作为大数据主流基础架构的Hadoop,在实际发展当中历经多次更新和迭代,而其中的HDFS架构,也是在不断完善和优化的。成都加米谷大数据,专业大数据培训机构,大数据开发、数据分析与挖掘,零基础班本月正在招生中,课程大纲及试学视频可联系客服领取!
- 上一篇:大数据培训:HDFS文件管理系统简介
- 下一篇:大数据学习:Hbase数据结构与算法




